
エグゼクティブサマリ
今回の調査で最も重要だった発見は、Codexは依然として「コーディングエージェント」だが、実際のプロダクト進化はすでに「コードを書く人だけの道具」から外へ広がっているという点です。OpenAIの公式ドキュメントと2026年のChangelogでは、Codexは研究、執筆、計画、分析、ソース収集、各種アーティファクト生成まで含む「より広い仕事のためのワークスペース」へ拡張されていると説明され、公式ユースケース群もGmail、Slack、Google Drive、Calendar、Google Sheets、Sites、Computer Useを前提とした知識労働・運用・資料作成・データ処理に大きく寄っています。つまり、非エンジニアにとっての本質は「コード生成そのもの」ではなく、自然言語で業務フローを記述し、裏側のコードやファイル処理を隠蔽したまま成果物を得ることです。
そのうえで、非エンジニア向けに最も現実的な導入先は三つあります。第一に、ドキュメント中心の仕事です。会議ブリーフ、PRD、スライド、学習用レポート、フィードバック統合のように、「入力は散在した文書群、出力はレビュー可能な文書」という業務は、Codexの公式想定と最も一致しています。第二に、スプレッドシート中心の仕事です。CSV整形、質疑応答、可視化、予実比較、キャッシュフローモデルのような仕事は、公式ユースケースでも明示され、学術研究でも自然言語による表計算操作は非技術者の障壁を下げる方向で進展しています。第三に、ノーコード寄りの社内アプリ試作です。OpenAI公式のSites、さらにCiscoのApp Builder事例は、「自然言語から動くアプリを立ち上げる」という非エンジニア寄りの導入像をかなり具体的に示しています。
一方で、楽観だけで整理すると判断を誤ります。Codexの価値は「完全自動化」ではなく「レビュー可能な半自動化」として見るのが妥当です。OpenAI自身が、Computer Useには権限承認が必要で、Cloudのインターネットアクセスはデフォルトで遮断、許可時もプロンプトインジェクションや秘密情報流出のリスクがあると明示しています。さらに、会議要約系の研究では幻覚や脱落が依然として課題であり、表計算研究でも実世界の複雑なシートは現行LLMにとって難所です。METRの2025年RCTでは、経験豊富なOSS開発者はAI利用時に平均で19%遅くなったという逆風の結果も報告されています。非エンジニアではなおさら、業務の切り出し方、入力の限定、検証フロー、承認境界が成果を左右します。
結論を先に言えば、非エンジニアに対するCodexの最適戦略は、広く一気に入れることではなく、狭い業務を深く置き換えることです。最初の一歩としては、「毎週ほぼ同じ構成で作る資料」「同じ種類のCSV整形」「会議準備の情報収集」「サポートチケットやSlackスレッドの分類」「既存業務の小さな社内ツール化」が成功しやすい領域です。逆に、「曖昧な要求をまたいで社内外の複数システムを自律操作する」「高リスクな顧客返信を人手なしで送信する」「評価基準が曖昧な創作を一発で本番投入する」といった用途は、現時点では設計・監督コストが高く、導入順位を下げるのが合理的です。
調査範囲とCodexの位置づけ
本レポートは、OpenAI公式のCodexユースケース集、Codex本体ドキュメント、ブログ、ヘルプセンター、日本語の公式ページを最優先に参照し、そのうえで学術論文と業界記事を重ねて評価しました。公式ユースケース一覧は、Automation、Data、Integrations、Knowledge Work、Finance、Operations、Product、Research、Salesといったフィルタを持ち、少なくとも表向きの設計意図として、Codexが開発作業だけではなく知識労働・業務運用・分析・資料作成の中間レイヤーに広がっていることを示しています。OpenAIの2026年4月16日Changelogも、project folder不要のChatsを「research, writing, planning, analysis, source gathering」に有効と明言しており、公式ポジショニング自体が非技術職に近づいています。
この整理は重要です。Codexは「ノーコードプラットフォーム」ではありません。OpenAIのトップページや日本語ページでも、Codexはまずソフトウェア開発エージェントとして説明されています。一方で、Skills、Plugins、MCP、Sites、Computer Use、Artifact Viewer、Automationsが揃った結果、非エンジニアがコードを直接書かなくても、コードを媒介に成果物や業務フローを得られるようになってきました。したがって、Codexの非エンジニア活用は「プログラミングを教えなくて済む」のではなく、プログラム可能性を自然言語・テンプレート・承認フローの背後に隠すアーキテクチャだと捉えるべきです。
日本語資料については、OpenAIは日本語の製品ページとヘルプセンター記事を提供していますが、ヘルプセンターのCodex記事は機械翻訳であることが明示されています。つまり、日本語導入は可能だが、一次情報の厚みは依然として英語が中心です。この点は、非エンジニア導入でありがちな「日本語で全部完結できる」という期待を少し下げておくべき根拠になります。
以下の図は、本レポートで整理した「非エンジニア向けCodex活用の全体像」です。公式ユースケースを中心に、学術研究で妥当性や限界が補強されたものを配置しています。
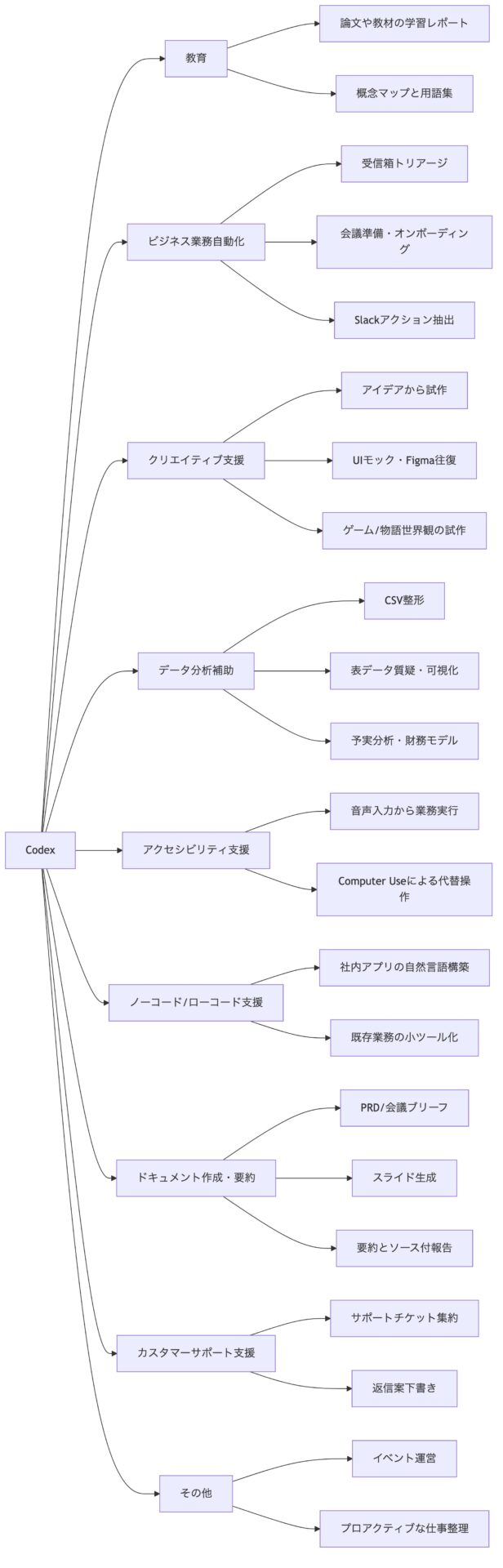
ユースケース分類と分析
教育 — OpenAI公式の「Learn a new concept」は、研究論文や講義資料をSubagentsで分担読解し、用語集・概念図・証拠表つきMarkdownレポートに落とす使い方を想定しています。これは「プログラミング学習」ではなく、難解資料の学習設計を外部化する用途です。利点は、読解の並列化、引用付きの学習ノート化、図解生成、未理解点の明示です。導入難易度は中程度で、素材の所在整理と「何を学べれば成功か」の定義が必要です。前提条件は、教材ファイル、参照可能なソース、曖昧な主張と自分の解釈を分ける評価ルールです。成功例としては、公式ユースケースそのものに加え、RAG型チュータは教師が与えたソースに基づくことで幻覚を抑えやすいとする研究があり、AIチュータが対面型アクティブラーニングより短時間で高い学習成果を示した報告もあります。他方で、教育研究では過信、浅い理解、主体性の低下、幻覚が一貫した懸念として挙がっており、「答えを出す装置」ではなく「学習の足場」として使う設計が必須です。
ビジネス業務自動化 — 公式には、受信箱管理、会議ブリーフ、オンボーディング、イベント運営、Slackアクション抽出、プロアクティブな仕事整理といった業務が細かくテンプレート化されています。共通点は、散在した文脈を集めて、レビュー可能な草案・チェックリスト・順位付きアクションへ変換することです。利点は、文脈切替の削減、抜け漏れ防止、ルーチン仕事の定時化です。導入難易度は低〜中で、Gmail、Slack、Calendar、Driveなどのプラグイン接続ができれば始めやすい反面、通知ノイズを減らすには継続チューニングが必要です。前提は、接続先の権限設定、どこまで下書きで止めるかという承認境界、Automationsの運用ルールです。成功例はOpenAI公式のワークフロー群自体に加え、OpenAI DevDay 2025でCodexが社内の問題解決・優先順位づけ・並行作業に広く使われたことです。失敗パターンは、広すぎる文脈を渡して重要度判定が崩れるケース、未承認の自動送信、権限を広く与えすぎるケースです。特にAutomationsは unattended 実行であるため、デフォルト権限とallowlist設計を曖昧にすると運用事故の温床になります。
クリエイティブ支援 — 公式には、「Get from idea to proof of concept」「Turn user stories into UI mocks」「Figmaとの双方向連携」が核です。つまりCodexの創造性支援は、純粋な文章生成よりも、曖昧な着想を視覚化し、試作し、比較可能な案に落とすところで強いです。ゲームデザイン支援も、公式ユースケースとSites/Showcase文脈から見ると、まずブラウザゲームや体験モックを作って試す方向が現実的です。利点は、形のないアイデアを短時間で視覚案・操作案・試作品に変えられることです。導入難易度は中程度で、要求の言語化と「評価観点」の提示が必要です。前提は、参考資料、ブランド/世界観ガイド、レビュー担当者です。成功例としては、OpenAI DevDay 2025でステージデモや体験プロトタイプにCodexが広く使われたこと、Figma MCPで“動くUIをFigmaに戻す”往復が可能になったことが挙げられます。一方、創造研究では、LLMは単純課題では発想刺激になっても、複雑課題では creative fixation を起こしうると報告されています。したがって、最初の案を採用するより、複数案比較を前提にした運用が向いています。
データ分析補助 — 非エンジニアにとって最も即効性が高いカテゴリです。公式には「Clean and prepare messy data」「Query tabular data」「Analyze datasets and ship reports」「Review budget vs. actuals」「Forecast cash flow」が揃っており、CSV整形、表データ質問応答、可視化、xlsx生成、予実差異分析までカバーしています。利点は、Excel/Sheetsの数式やスクリプトを書かずに、自然言語から分析作業へ入れることです。導入難易度は低〜中で、単発QAや整形なら始めやすく、財務モデルや複数ソース結合は中級以上です。前提は、元データの所在、列の意味、出力形式、そして「変更前データを保持する」原則です。成功例は公式のスプレッドシート系ユースケースに加え、近年の研究でSheetMindが「スクリプトや数式知識なし」での会話型表計算操作を狙い、単一ステップ80%、複数ステップ約70%の成功率を報告したこと、TableTalkが認知負荷を下げ、好ましさを高めたことです。失敗例・制約としては、SpreadsheetBenchが現実のExcelフォーラム由来タスクを難問として示し、SpreadsheetLLMがシートの2次元構造とトークン長制約を問題視している通り、実務の複雑表計算は依然として難しいという点です。要するに、Codexは「万能Excel代替」ではなく、「質問・整形・可視化・レビュー用ワークブック作成」にまず投資すべきです。
アクセシビリティ支援 — これはCodex単体のネイティブカテゴリというより、CodexとOpenAIの音声・Realtime・Computer Useを組み合わせた周辺活用です。公式にはComputer UseがmacOS/Windows上のGUI操作を担当し、Speech-to-Text、Text-to-Speech、Voice Agents、Realtimeが代替入力や音声UIの基盤を提供します。利点は、キーボード中心の操作が難しい場面でも、音声で依頼し、Codexがアプリやブラウザを操作して成果物を返せることです。さらにAppshotsは、Mac上の前面ウィンドウをショートカットでCodexに渡せるため、長い状況説明の代替入力としても機能します。導入難易度は中〜高で、音声UIの設計、権限設定、誤操作対策が要ります。前提は、Screen Recording / Accessibility権限、利用アプリの可視状態、音声認識品質の確認です。成功例は、公式の音声エージェント構成やComputer Useのワークフロー説明そのものです。制約としては、Computer Useがアプリ状態を変えうること、音声系は日本語を含む多言語対応がある一方で、非英語環境ではAI支援の効果差が生じうるとする研究があること、そしてCodex公式にはアクセシビリティ専用UXの詳細設計までは出ていないことです。したがって、このカテゴリは補助技術としての価値は高いが、完成品ではなく設計対象だと見るのが正確です。
ノーコード/ローコード支援 — 非エンジニアへの波及が最も大きいのはここです。OpenAI公式の「Build and deploy internal apps」とSitesは、Codexに自然言語で社内アプリを作らせ、保存・デプロイ・認証つきで配布する流れを提供しています。Ciscoはさらに一歩進めて、Cloud Control内にApp Builderを組み込み、「plain languageで、インフラ構築なし、最初からデプロイ済みのアプリ」を打ち出しました。利点は、既存業務の手順やフォームや一覧画面を「雑用としての開発」なしに試せることです。導入難易度は中〜高で、要件定義、データモデル、権限設計、レビュー体制が必要です。前提は、扱うデータの所在、認証要件、公開範囲、変更管理です。成功例として、Ciscoはパートナー/顧客向けに自然言語からアプリを組み立てる事例を提示しています。失敗リスクは、要件が曖昧なまま試作を量産して運用負債を増やすこと、LLMと非専門家のあいだに abstraction gap があり「モデルが欲しがる言い方」にこちらが合わせてしまうことです。研究でも、非専門家はコード生成LLMに対し意図の伝え方で躓きやすいとされ、TableTalkや関連研究は足場づくりを重視しています。つまり、ノーコード化の本体はモデル性能ではなく、テンプレート・制約・確認工程の設計です。
ドキュメント作成・要約 — ここはCodexの公式想定が非常に明確です。PRD草案、会議ブリーフ、学習レポート、スライド、フィードバック要約はすべて公式ユースケース化されています。利点は、ソース群からレビュー可能なアーティファクトへ直接変換できる点で、2026年4月のArtifact Viewer追加により、PDF・スプレッドシート・文書・プレゼンをサイドバーで確認できるようになったことも非エンジニアには重要です。導入難易度は低〜中で、特に会議ブリーフ・PRD・スライドは始めやすい領域です。前提は、参照ソースの限定、出力の型、改稿責任者です。成功例としては、各公式ユースケースに加え、OpenAIがSuperhumanの例として「PMが軽微なコード変更に寄与できる」ことを示した点も、ドキュメントから実装への距離が縮んでいる象徴です。失敗例・制約としては、会議要約研究が幻覚・脱落・irrelevancyを引き続き報告していること、要約研究全体でもfaithfulnessが未解決であることです。文書化領域は強い一方で、一次情報との対応表を残すソース付けが品質管理の中心になります。
カスタマーサポート支援 — OpenAIは「Support」専用カテゴリこそ大きく打ち出していませんが、実務上はかなり近いユースケースを揃えています。「Turn feedback into actions」は support-ticket CSVs を明示し、Google Sheet/Doc/Slack updateへの集約を想定しています。「Manage your inbox」は返信案の草稿化、「Prioritize Slack action items」は support・community・operations での優先順位づけを明示しています。利点は、問い合わせの分類、重複要望の集約、返信草案、エスカレーション候補抽出です。導入難易度は低〜中で、すでにGmailやSlackを使っているチームは始めやすいです。前提は、個人情報のマスキング規則、公に見せる要約と内部メモの分離、Human-in-the-loopです。成功例としては、公式スタータープロンプトが「名前や私的引用を visible summary に入れない」ことまで明示しており、サポート運用の実務にかなり近いです。失敗パターンは、顧客感情や文脈を雑に圧縮すること、未承認の送信、自動分類に過度依存することです。よってこのカテゴリでは、送信前承認を外さないことが事実上の必須条件です。
その他 — 公式ユースケースを見ると、非エンジニア活用は実際には「未分類の小さな業務バンドル」に強いです。Messagesからタスクを完了する、イベント運営の公開文面と内部チェックリストを分離する、オンボーディング一式を下準備する、日々の重要事項だけ拾う“teammate”スレッドを作る、といった仕事がそれに当たります。これらは単独カテゴリよりも、“散った文脈を短時間で行動可能な形へ変える”というCodexの汎用能力を示しています。公開成功例は個別には少ないものの、Ciscoの事例やOpenAI社内活用を見る限り、価値は大きなシステム構築より「日々の摩擦を減らす小粒な反復作業」に出やすいと見るのが妥当です。
比較表と導入優先順位
以下の比較表でいう「導入コスト」は、Codexと既存SaaSを前提にした追加導入コストの概算です。低は既存のChatGPTプランと既存業務データで試せるもの、中はプラグイン接続・レビュー手順整備が必要なもの、高はBusiness/Enterprise、Sites、権限設計、監査、あるいは専用ワークフロー整備が必要なものとして整理しました。Codex自体はFree/Go/Plus/Pro/Business/Edu/Enterpriseに含まれますが、Sitesは現時点でBusiness/Enterprise中心、API key運用はクラウド機能が限定されます。
| カテゴリ | 代表ユースケース | 必要スキル | 導入コスト概算 | 時間短縮効果 | 推奨ツール / プラットフォーム | 主要根拠 |
|---|---|---|---|---|---|---|
| 教育 | 論文・教材から学習レポート作成 | 目的設定、資料選定、レビュー | 低〜中 | 高 | Codex app / Subagents / ImageGen | |
| ビジネス業務自動化 | 受信箱管理、会議ブリーフ、Slackアクション抽出 | 業務整理、承認設計 | 低〜中 | 高 | Gmail / Slack / Calendar / Drive / Automations | |
| クリエイティブ | アイデア→モック→試作 | 企画言語化、評価観点設定 | 中 | 中〜高 | ImageGen / Figma MCP / Sites | |
| データ分析補助 | CSV整形、可視化、予実比較 | データ列理解、検算 | 低〜中 | 高 | Spreadsheet skill / Google Sheets / Artifact Viewer | |
| アクセシビリティ支援 | 音声依頼、代替入力、GUI操作 | 誤操作防止、権限設定 | 中〜高 | 中 | Voice Agents / Realtime / Speech-to-Text / Computer Use / Appshots | |
| ノーコード/ローコード支援 | 社内アプリ試作・公開 | 要件定義、データモデル、運用責任 | 中〜高 | 高 | Sites / Skills / MCP / Business or Enterprise workspace | |
| ドキュメント作成・要約 | PRD、会議資料、スライド、要約 | 出力形式定義、ソース確認 | 低 | 高 | Google Drive / Docs / Slides / Artifact Viewer | |
| カスタマーサポート支援 | チケット統合、返信草稿、優先度付け | PII管理、返信承認 | 低〜中 | 高 | Gmail / Slack / Google Sheets / Drive | |
| その他 | イベント運営、オンボーディング、日次トリアージ | ルール化、チェックリスト運用 | 低〜中 | 中〜高 | Slack / Calendar / Drive / Codex teammate thread |
導入優先順位としては、第一群が文書化と表計算、第二群が業務トリアージ、第三群が社内アプリ試作、第四群が代替入力や複雑なCross-app自動化です。理由は単純で、入力と出力の検証可能性が高いほどCodexの価値が出やすく、エラーの社会的コストが低いからです。逆に、顧客送信・権限変更・GUI自動操作が前面に出るほど、メリットはある一方で監督コストが急増します。
非技術者向けの技術要約と実践ガイド
非技術者向けにCodexを一文で言い換えるなら、「自然言語で依頼すると、ファイル・表・文書・アプリ・ウェブ操作まで含めて、レビュー可能な成果物を作る仕事エージェント」です。機能面では、ローカルまたはクラウドで作業し、コードや文書を読み書きし、コマンドを実行し、プラグイン経由でGmail/Drive/Slackを扱い、必要に応じてComputer UseでGUIを操作し、Sitesでホスト済みサイトや社内アプリを配布できます。さらにSubagentsで作業を並列化し、Automationsで同じスレッドを定期的に再実行できます。こうして見ると、非エンジニア活用の本質は「プログラムを書くこと」より「成果物と承認フローを設計すること」にあります。
制約ははっきりしています。第一に、Codexは一般的な万能秘書ではなく、あくまで“作業可能なエージェント”です。だからこそ権限境界が重要で、Permissionsには read-only / workspace / danger-full-access が用意され、Cloud側のインターネットアクセスもデフォルトでは遮断されています。第二に、Computer UseやBrowser Useは便利ですが、外部アプリの状態を変えうるので「狭いタスク」「明確な対象アプリ」「都度承認」が前提です。第三に、In-app browserは認証フローや既存Cookieを扱えず、公式もサインインが必要なページは通常ブラウザを使うよう勧めています。第四に、言語面ではOpenAIは日本語の製品ページとヘルプ記事を提供し、音声系APIも日本語を含みますが、Codex専用の言語対応表は今回確認できず、非英語運用の質はプロンプト設計と検証に左右されます。
歴史的な性能の見方も補足しておくべきです。2021年の原初Codex論文ではHumanEval pass@1が28.8%でしたが、これは現在のGPT-5系Codexとは世代もエージェント構成も異なるため、そのまま比較してはいけません。むしろ現在の実務上の重要点は「一発正解率」より長いタスクをどれだけ整合的に追い続けられるかです。OpenAIは25時間・約1300万トークン・約3万行の長時間Codex実験を公開し、METRはフロンティアAIエージェントのタスク時間軸が過去6年で約7か月ごとに倍化していると報告しています。ここから言えるのは、Codexの非エンジニア活用も「短い質問応答」より「数十分〜数時間かけてアーティファクトを作らせる」方へ重心が移っているということです。
実践ガイドは、次の順で進めるのが最も堅実です。まず、業務を「毎週繰り返す」「入力ソースが限られる」「出力フォーマットが固定されている」ものに絞ります。次に、使う面を選びます。文書・表計算・資料ならCodex appやChats、社内アプリならSites、Slack駆動ならSlack integration、GUI必須ならComputer Useです。そのうえで、ソース境界、非目標、出力形式、承認境界をプロンプトに明示します。たとえば「Gmailだけを参照」「未送信の下書きまで」「Google Sheetで出力」「個人名は要約に入れない」のように、守らせたい境界を先に書きます。続いて、小さなサンプルで試し、差分レビューを行い、最後にAutomationsやSkillsで定型化します。この順番は、OpenAIのスタータープロンプト群、Best Practices、Permissions、Automationsの設計思想と整合しています。
導入タイムラインは、実務では4週間程度の小さなパイロットが適切です。大事なのは、PoCを「できたかどうか」で終えず、人手レビュー込みで、どこまでなら任せられるかを切り分けることです。特に会議要約、顧客返信、財務ワークブック、GUI操作は、最終承認の責任者を最後まで残す方が総合的な品質が安定します。

代表プロンプトテンプレートと主要出典
以下のテンプレートは、OpenAI公式のスタータープロンプト群を日本語業務向けに再構成したものです。ポイントは、入力ソース、出力形式、境界条件、承認条件、除外事項を必ず含めることです。これは公式スタータープロンプトでも繰り返し見られる設計であり、非エンジニア運用ではここを曖昧にすると品質が急落します。
| 用途 | 日本語テンプレート | 参考 |
|---|---|---|
| 学習レポート | 「この資料群から『[概念名]』を学びたいです。資料を分担して読み、①要点の要約 ②用語集 ③概念マップ ④証拠表 ⑤限界と未解決点 をMarkdownで作成してください。論文の主張とあなたの解釈は分けて書き、根拠の弱い点は弱いと明記してください。」 | |
| 受信箱整理 | 「@gmail を見て、今日対応が必要なメールだけを抽出してください。出力は『優先度 / 要約 / 下書き案 / 要確認点』の表にしてください。送信は行わず、下書き作成までに止めてください。私的情報や確証のない推測は入れないでください。」 | |
| 会議準備 | 「@google-calendar と @google-drive と @slack と @gmail を使い、[会議名]の事前ブリーフを作ってください。目的、参加者別の論点、確認すべき数字、未決事項、当日のメモ枠を1枚にまとめてください。根拠ソースを末尾に残してください。」 | |
| フィードバック統合 | 「@slack の指定チャンネル、@google-drive の調査メモ、添付のCSVを使って、[機能名]に関するフィードバックを統合してください。重複意見は束ね、証拠リンクを残し、プロダクト対応・サポート対応・様子見に分類してください。個人名は見える要約から外してください。」 | |
| CSV整形 | 「添付CSVを整形してください。問題は、日付形式の混在、通貨記号の混在、重複行、集計行の混入です。元データは変更せず、クリーン版CSVと、変更・削除・保留の行をまとめた品質メモを作成してください。」 | |
| 表データ分析 | 「添付の売上データを分析してください。まず列を確認し、その後『先四半期で最も変化した顧客セグメントはどれか』に答えてください。ブラウザで見られる簡易グラフも作り、最後に会議で読める短い要約文を付けてください。」 | |
| 予実分析 | 「予算、実績、月次メモの3ファイルを使い、予実差異レビュー用の.xlsxを作ってください。原本は保持し、差異計算は数式で残し、マッピングに自信がない科目は無理に合わせずフラグを立ててください。最後に経営会議前に人が確認すべき論点を列挙してください。」 | |
| スライド作成 | 「この会議メモと参考資料から、社内共有用の10枚以内のスライドを作ってください。構成は『背景 / 現状 / 主要発見 / 推奨アクション / 次の一手』にしてください。図表は簡潔にし、各スライドに1メッセージだけ載せてください。」 | |
| 社内アプリ試作 | 「@sites を使って、[チーム名]向けの小さな社内アプリを作ってください。目的は[例: 申請の受付と一覧管理]です。最初の版は1つの業務に絞り、必要な入力項目、一覧表示、更新履歴だけを実装してください。公開前にテスト観点と確認事項を出してください。」 | |
| サポート支援 | 「サポートチケットCSVとSlackの関連スレッドから、今週の主要問い合わせテーマをまとめてください。『件数 / 代表例 / 影響度 / 既知の回避策 / プロダクトへの引き継ぎ有無』で整理し、顧客向け返信文ではなく内部レビュー資料として出してください。」 |
最後に、主要出典を性質別に整理します。
OpenAI公式の中核資料としては、Codex use cases一覧、各ユースケース個票、Codex app、Plugins、Sites、Computer Use、Automations、Permissions、Internet Access、Pricing、Changelog、Introducing Codex、Building frontend UIs with Codex and Figma、How Codex ran OpenAI DevDay 2025、日本語製品ページ、日本語ヘルプ記事が最重要です。
学術一次資料としては、Codex原論文、NL2Formula、SpreadsheetBench、SpreadsheetLLM、SheetCopilot、SheetAgent、SheetMind、TableTalk、abstraction gap研究、要約のfaithfulness研究、教育系のRAGチュータ・AIチュータ研究、教育リスク研究が実務判断に役立ちます。特に、表計算と要約は「可能性」と「難所」がどちらも強く可視化されている領域です。
業界事例としては、OpenAI × Ciscoのケーススタディ、CiscoのApp Builder発表、OpenAIが挙げるSuperhumanのPM活用、Ciscoブログの初期パートナー記事が、非エンジニアや周辺職種への波及可能性を最も具体的に示しています。特にCiscoの「plain languageでアプリを作る」「born deployed」という表現は、Codexが“非エンジニア向けにどう包まれると価値が立ち上がるか”を示す好例です。
総括すると、Codexの非エンジニア向けユースケースは「コードを書かせること」よりも、仕事を構造化し、レビュー可能な中間成果物を作り、必要なときだけ人が最終判断する運用に置いたときに最大化されます。現時点での最適解は、文書系・表計算系・小規模社内アプリ系から入り、顧客送信や広範なGUI自動操作は後段に回すことです。これが、公式ソース、学術研究、事例を重ねたときに最も整合的な導入戦略です。



