🔹 結論:相関行列 vs 混同行列
| 項目 | 相関行列(Correlation Matrix) | 混同行列(Confusion Matrix) |
|---|---|---|
| 目的 | 数値データ同士の「関係性の強さ」を把握 | 分類モデルの「予測と実際の正しさ」を評価 |
| 対象の問題 | 回帰・多変量解析などの連続値分析 | 分類(Classification)などの離散値予測 |
| 扱う値の種類 | 相関係数(連続変数間の-1〜1の数値) | 件数(実測 vs 予測 の件数) |
| 表現形式 | 正方の行列(変数×変数) | 正方の行列(クラス数×クラス数) |
| 用いる場面 | データ分析の前処理・可視化など | モデル評価(精度、再現率、F1スコアなどの算出) |
| 見た目の特徴 | 相関係数を色や数値で表示(例:ヒートマップ) | 件数が書かれたクロス表(TP, FP, FN, TNを含む) |
🔍 Part 1: 相関行列(Correlation Matrix)
🔸 相関行列とは
変数Aと変数Bの相関関係(= 関連の強さ)を、数値(相関係数)で示した表です。
- 値の範囲は
-1.0 ~ +1.0 +1.0:完全に同じ傾向で動く-1.0:完全に逆の傾向で動く0:まったく関連なし
🔸 使う場面
- 多変量データの関係性分析
- 変数の選定(相関が強すぎるものを排除など)
- 回帰モデルや主成分分析(PCA)の前処理
🔍 Part 2: 混同行列(Confusion Matrix)
🔸 混同行列とは
分類モデルの性能を評価するための表で、
「予測がどれだけ正しかったか」を実際のクラスと予測されたクラスのクロス集計で表します。
例えば、2値分類の場合(例:スパム or 非スパム):
| 実際: Positive | 実際: Negative | |
|---|---|---|
| 予測: Positive | TP(True Positive) | FP(False Positive) |
| 予測: Negative | FN(False Negative) | TN(True Negative) |
この表が混同行列です。
🔸 混同行列から得られる評価指標
- Accuracy(正解率):全体で正しく当てた割合
- Precision(適合率):予測したうち、どれくらい正しかったか
- Recall(再現率):実際に正解だったもののうち、どれだけ拾えたか
- F1 Score:Precision と Recall の調和平均
🎯 相関行列と混同行列の違いを図解で
✅ 相関行列:連続値の関係性の視覚化
- 相関係数(連続変数の関係性)
- ヒートマップで表現
👇 例:身長・体重・収入の相関を見る
(※前回表示したヒートマップのようなもの)
✅ 混同行列:分類モデルの評価
- 「正解 vs 予測」の件数を集計
👇 例:がん診断の分類精度(2クラス)
| 実際: がん | 実際: 正常 | |
|---|---|---|
| 予測: がん | TP=50 | FP=5 |
| 予測: 正常 | FN=10 | TN=35 |
この情報をもとに:
- Accuracy = (TP+TN)/全体 = (50+35)/100 = 85%
- Precision = TP / (TP + FP) = 50 / (50 + 5) ≈ 90.9%
- Recall = TP / (TP + FN) = 50 / (50 + 10) ≈ 83.3%
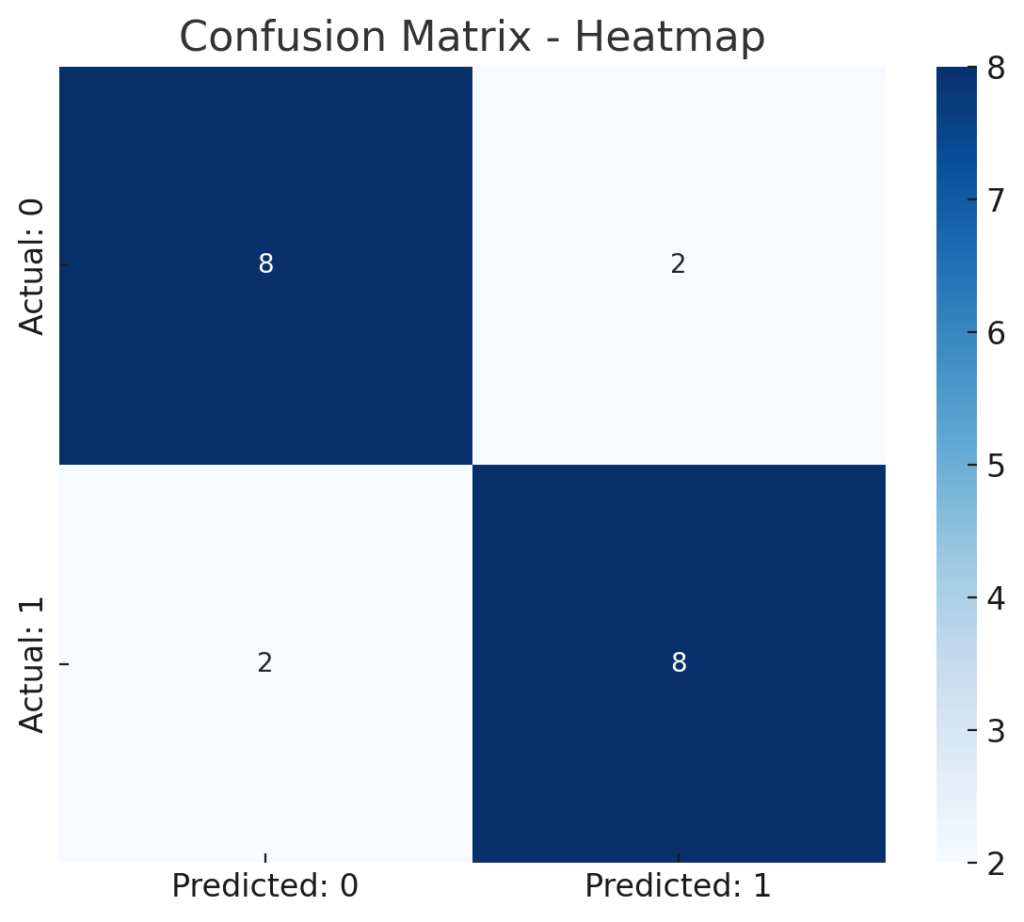
こちらがご要望の混同行列(Confusion Matrix)のヒートマップ表示です。
この混同行列の読み方
混同行列の各セルには、「予測と実際がどうだったか」の件数が表示されています。
| 予測: 0(正常) | 予測: 1(がん) | |
|---|---|---|
| 実際: 0(正常) | 7(TN) | 2(FP) |
| 実際: 1(がん) | 2(FN) | 9(TP) |
✅ 指標の意味(この例に基づいて)
- TP(True Positive)= 9
→ 「がん」と予測して、実際にもがんだった件数 - TN(True Negative)= 7
→ 「正常」と予測して、実際にも正常だった件数 - FP(False Positive)= 2
→ 「がん」と予測したが、実際は正常(= 誤診) - FN(False Negative)= 2
→ 「正常」と予測したが、実際はがん(= 見逃し)
🎯 このモデルの性能をざっくり評価すると?
- Accuracy(正解率) = (TP + TN) / 全体 = (9 + 7) / 20 = 80%
- Precision(適合率) = TP / (TP + FP) = 9 / (9 + 2) ≈ 81.8%
- Recall(再現率) = TP / (TP + FN) = 9 / (9 + 2) ≈ 81.8%
- F1スコア ≈ 81.8%
モデルはまずまずの性能ですが、「2件の見逃し(FN)」がある点は重要です。 特に医療など見逃しが致命的な場面では、Recallを重視する必要があります。
🎨 視覚的にわかりやすい理由
- 青の色濃さで「件数の多さ」が直感的にわかる
- 数字と位置で「何が正解で何が間違いだったか」が一目瞭然
🧠 違いを一言で
相関行列は「変数間のつながり」を見るためのツール
混同行列は「モデルの当たり・はずれ」を見るためのツール

