第1章:長文コンテキストの必要性とそれに伴う課題
1.1 LLMコンテキストウィンドウの進化
大規模言語モデル(LLM)の能力を定義する上で、コンテキストウィンドウのサイズは極めて重要な指標となっている。初期のモデル、例えばBERTは512トークンという比較的短いシーケンスしか扱えなかったが、技術の進歩は目覚ましく、現代の最先端モデルであるGemini 1.5 Proは最大1,000万トークンという桁違いのコンテキスト長をサポートするに至っている 1。この拡張は単なる量的な飛躍ではなく、質的な変革をもたらした。書籍全体の要約、複雑な法的契約書の分析、あるいは長時間にわたる複数ターンの対話の一貫性維持といった、かつては不可能であった応用が現実のものとなりつつある 7。この進化の背景には、LLMを単なる指示追従システムから、複雑なアプリケーションの中核をなす推論エンジンへと昇華させたいという強い動機が存在する 11。
1.2 完全なリコールの幻想
長文コンテキストウィンドウに対する初期の熱狂は、より大きな「ワーキングメモリ」12が、広範な情報統合を必要とするタスクの性能を比例的に向上させるだろうという期待に基づいていた。しかし、実用的な応用と厳密な評価が進むにつれて、より複雑な現実が明らかになり始めた。モデルが情報を利用する能力は、コンテキストウィンドウ全体にわたって均一ではないという事実である 13。入力された情報の位置によって、モデルがその情報にアクセスし、活用する能力が大きく変動することが示された。これは、コンテキストウィンドウの拡大という工学的偉業が、その広大な空間全体で均一な注意(アテンション)を保証するために必要な根本的なアーキテクチャ革新のペースを上回ってしまったことを示唆している。結果として、モデルは長文の入力を「受け入れる」ことはできるが、その全体にわたって確実に「推論する」能力には課題が残るという「能力のギャップ」が生じている。
1.3 位置バイアスの導入
LLMにおける不均一な情報利用能力は、「位置バイアス」という形で体系的に現れる。このバイアスは主に二つの形態を取る。
- 初頭効果(Primacy Bias): モデルが入力コンテキストの冒頭に提示された情報に対して、より大きな重みを置く、あるいはより正確に想起する傾向 7。
- 親近効果(Recency Bias): 同様に、入力コンテキストの末尾に提示された情報を優先的に利用する傾向 7。
これらのバイアスが組み合わさることで、性能のランドスケープが形成される。コンテキストの冒頭と末尾はモデルの注意が集中する「スポットライト」領域となり、その中間部分は相対的に影の中に置かれることになる 15。この現象こそが、次章で詳述する「Lost in the Middle」問題の核心である。
第2章:「Lost in the Middle」現象の定義と定量化
2.1 独創的研究:Liu et al. (2023/2024)
「Lost in the Middle」(LITM)という現象を学術的に定義し、その存在を実験的に証明した独創的な研究が、Liuらによる論文「Lost in the Middle: How Language Models Use Long Contexts」である 7。この研究の核心的な発見は、LLMの性能が、長文コンテキストの中間部分に位置する関連情報にアクセスする必要がある場合に著しく低下するという点にある。この傾向は、特に長文コンテキストを扱うために明示的に設計されたモデルにおいてさえも見られた 7。さらに、この現象は指示チューニングされたモデルに限定されるものではなく、ベースモデル(事前学習のみでチューニングされていないモデル)でも同様に観測されることが確認されている 19。
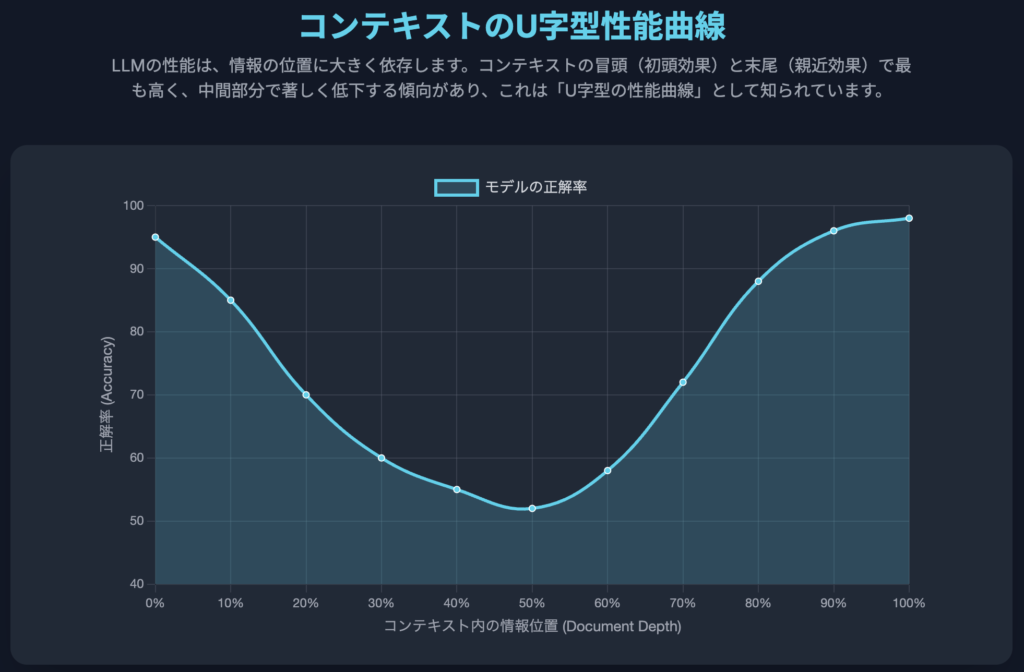
2.2 U字型の性能曲線
LITM現象を最も象徴的に可視化したのが、「U字型の性能曲線」である 7。このグラフは、縦軸にモデルの正解率(Accuracy)、横軸に関連情報がコンテキスト内に配置された位置(Document Depth)を取ることで生成される。性能はコンテキストの冒頭(初頭効果)と末尾(親近効果)で最も高くなり、中間部分で大きく落ち込むため、グラフは明確な「U」の字を描く 7。このパターンは、人間が長いリストや書籍の内容を記憶する際に、最初と最後の章はよく覚えているが、中間の章の内容は曖昧になりがちな現象と類似している 21。
2.3 主要な実験パラダイム
LITM現象を測定し、定量化するために、いくつかの標準的な実験手法が確立されている。
- 複数文書質問応答(Multi-Document Question Answering, MDQA): これはLiuらの元論文で中心的に用いられたタスクである。実験設定は、モデルに一つの質問と複数の文書群を与え、そのうちの一つの文書にのみ答え(「針」)が含まれ、他の文書は無関係な「攪乱情報」(「干し草の山」)として機能する 7。文書の順序を入れ替えることで、研究者は答えの位置を正確に制御し、各位置におけるモデルの正解率を測定することができる 7。
- 合成キー・バリュー検索: より制御されたタスクとして、モデルにキーとバリューのペアの集合を与え、指定されたキーに対応するバリューを検索させるものがある 13。このタスクは、複雑な推論要素を排除し、純粋な情報検索能力に焦点を当てる。それでもなお、性能はU字型の曲線を示すことが確認されている。
- 「Needle in a Haystack」(NIAH)ベンチマーク: Greg Kamradtによって広められ 24、現在では長文コンテキストのリコール能力を評価するための事実上の標準となっている 26。このテストでは、無関係なテキスト(例:ポール・グレアムのエッセイ集)からなる広大なコーパスの中に、単一の、しばしば文脈とは無関係な情報(例:「サンフランシスコで一番すべきことは…」)を埋め込み、モデルがそれを検索できるかを評価する 24。その方法論、利点(単純さ、スケーラビリティ)、そして弱点(推論ではなくリコールのみをテストする)について、後のセクションで詳細に議論する 6。
これらの実験手法は、LITMが特定のタスクやデータセットに限定されない、LLMのアーキテクチャに根差した普遍的な課題であることを示している。しかし、特にNIAHベンチマークの広範な採用は、長文コンテキストの有用性という問題を単純な検索・取得タスクに過度に単純化してしまう危険性をはらんでいる。この「ベンチマークの幻想」は、モデルが「針を見つける」ことには長けているが、長文コンテキストモデルの真の可能性である「干し草の山」全体にわたる情報の統合や推論といったタスクでは依然として失敗するという状況を生み出しかねない。実際に、MDQAのような推論を伴うタスクから、純粋なリコールタスクであるNIAHへと評価の主流が移ったことで、業界はより測定しやすい指標に最適化を進めてきた。Gemini 1.5 ProやClaude 3 OpusのようなモデルがNIAHでほぼ完璧なスコアを記録する一方で 4、Loong(全文書にわたる推論を要求)やNoLiMa(字句的な重複を排除)といったより複雑で現実的なベンチマークでは、これらのトップモデルでさえも依然として大きな困難に直面している 28。この乖離は、業界が単純化された代理タスクでの成功を祝う一方で、複雑な長距離推論という核心的な課題が未解決のままであるという重大な問題を浮き彫りにしている。NIAHのスコアだけに基づいてLITM問題が「解決済み」であると時期尚早に結論付けてしまうことは、きわめて危険である。
第3章:メカニズムの基礎:Transformerアーキテクチャへの深い洞察
LITM現象の根本原因を理解するためには、Transformerモデルの内部構造、特に自己注意機構(Self-Attention Mechanism)と位置エンコーディング(Positional Encoding)の動作を詳細に分析する必要がある。
3.1 自己注意機構
- 二次的な計算量: Transformerの心臓部である自己注意機構は、入力内の全てのトークンペア間で注意スコアを計算する 34。これにより、計算量とメモリ要件はシーケンス長
nに対して二次関数的に増大する(O(n2)) 8。このスケーラビリティの問題が、より効率的な「スパース」アテンション機構の研究を推進する主要な動機となっている 35。 - アテンション分布とSoftmax: アテンションスコアを確率分布に変換するために使用されるSoftmax関数は、非常に長いコンテキストに適用されると、その確率質量が広範囲に拡散しすぎる(”diffuse”になる)ことがある 9。これにより、特定の情報片に対する集中力が失われ、モデルが注意を払うべきトークンが最も多い中間部分での性能低下の一因となる。
3.2 因果的アテンションマスクと位置的隠れ状態
- 自己回帰型のデコーダ専用モデルでは、**因果的アテンションマスク(Causal Attention Mask)**が適用され、各トークンが未来のトークンに注意を向けることを防ぐ 39。これにより、情報が一方向にしか流れないという、ハードコードされた非対称性が生まれる。
- 近年の研究では、このマスクが中立的なものではなく、位置エンコーディング自体とは独立して、トークンの絶対位置と相関する「位置的隠れ状態(Positional Hidden States)」を生成することが示されている 41。これは、シーケンスの冒頭に向かって本質的にバイアスのかかった、もう一つの位置情報源となり、初頭効果を増強する一因となっている。
3.3 主要因としての位置エンコーディング(PE)
Transformerはトークンを並列に処理するため、本質的にシーケンスの順序を理解できない。この情報を提供するために、PEがトークン埋め込みに加算される 45。
- 絶対/学習済みPEの限界: GPT-3のようなモデルで使用される学習済みPEは、訓練時に遭遇したよりも長いシーケンスに汎化できず、厳格なコンテキストウィンドウの制限を生み出す 47。
- 回転位置埋め込み(Rotary Position Embeddings, RoPE): Llamaなど、現代のオープンソースLLMで主流となっているPE。RoPEは、クエリベクトルとキーベクトルを回転させることで相対的な位置情報をエンコードする 9。しかし、RoPEには「長距離減衰(long-term decay)」特性があり、距離が離れるにつれてアテンション信号が自然に弱まる 49。この減衰は、非常に長いシーケンスの最後のトークンから見て、中間にあるトークンに注意を向けることの難しさに直接的に寄与する。
- ミクロレベルの表現としてのアテンションパターン: マクロレベルで観測されるU字型の性能曲線は、ミクロレベルのアテンション重みパターンの直接的な結果である。分析によると、検索に特化した層では、正解情報に割り当てられるアテンション重みは、コンテキストの冒頭と末尾で最も高く、中間で最も低くなり、性能曲線と完全に一致するパターンを示す 41。
LITM現象は単一の欠陥ではなく、少なくとも3つの異なるアーキテクチャコンポーネントの相互作用から生じる創発的な特性であると理解することが重要である。(1) 長いシーケンス上でのSoftmax関数の拡散効果、(2) 因果的マスクがもたらす時間的なバイアス、そして (3) RoPEの距離に基づく減衰。この「三重の脅威」が、強固で解決困難なバイアスを生み出している。この複雑な相互作用は、なぜ単純な修正がしばしば失敗するのかを説明する。例えば、PEをALiBiに変更するだけでは、減衰の問題は緩和されるが、因果的マスクのバイアスは解決されない。したがって、LITMに対する頑健な解決策は、PE、アテンション分布、そして場合によっては因果的構造自体にも対処する、多角的なアプローチを必要とする。
第4章:実用的な影響とハイステークスな応用におけるリスク
このセクションでは、抽象的な技術的問題を、具体的で現実世界のリスクと結果に落とし込み、LITMの解決がなぜ重要なビジネスおよび安全性の要請であるかを強調する。
4.1 検索拡張生成(RAG)への影響
RAGシステムは、検索した文書をLLMのコンテキストに入力して回答を生成する 52。LITM現象は、このアーキテクチャにとって大きな課題となる。
- 飽和点(The Saturation Point): 研究によると、コンテキストに文書を追加することは、ある特定の「飽和点」までは性能向上に寄与する。しかし、その点を超えると、重要な情報が関連性の低い、あるいは「攪乱情報」となる文書に囲まれて中間部分に埋もれてしまい、性能が実際に低下する可能性がある 5。
- トレードオフ: これにより、RAGの開発者は困難なトレードオフに直面する。答えを見つける確率を高めるためにより多くの文書を検索する(リコールを向上させる)か、しかしその結果、答えを「中間」に押しやり、生成器がそれを利用する能力を低下させるリスクを冒すか、というジレンマである 8。
4.2 ドメイン固有のリスク
LITMが専門的なドメインでいかに致命的な失敗を引き起こしうるか、具体的な例を以下に示す 8。
- 法務: 100ページの契約書をレビューするモデルが、2ページ目と98ページ目の条項は正しく特定する一方で、55ページ目に記載された重大な責任免除条項を完全に見落とし、悲惨な法的助言につながる可能性がある 21。
- 医療: 患者の広範な医療履歴を要約する際、モデルは初期診断と最新の治療計画は正確に把握するかもしれないが、記録の中間に記された特定の薬剤に対する重大なアレルギー反応を見逃し、生命を脅かす結果を招く可能性がある 21。
- 金融: 四半期財務報告書を分析するタスクを課されたLLMが、冒頭の経営陣による概観と末尾の将来見通しは完璧に要約する一方で、企業の財務健全性を根本的に変える重要な減損処理を詳述した中間部分の脚注を見落とす可能性がある 21。
- カスタマーサポート: 長い顧客とのやり取りの履歴を分析するサポートボットが、対話の中間で言及された元の問題点を追跡できなくなり、苛立たしく無関係な応答を生成する可能性がある 21。
LITM現象は、ハイステークスな長文シナリオにおいて、LLMを強力なツールから信頼性の低いツールへと変えてしまう。それは、内容だけでなく文書の構造に依存する、隠れた非決定論的な障害モードを導入する。これにより、ミッションクリティカルなタスクに対するLLMの出力を監査し、信頼することが極めて困難になる。例えば、ある組織が契約書レビューの迅速化のためにLLMを導入したとする 21。短い文書や、重要な条項が冒頭か末尾にある長い文書では良好な性能を示すかもしれない。しかし、本番環境で、重要な「オプトアウト」条項が80ページ中40ページ目にある契約書を処理した場合、LITMに陥ったLLMはその条項を要約から見落とす。要約に依存した法務チームが契約を承認し、企業は免除されていると信じていた条件に拘束されることになる。この失敗は、モデルが法律を「知らなかった」り、「ハルシネーション」を起こしたりしたためではない。それはアテンションの構造的な失敗である。これは、標準的な内容ベースの評価では容易に検出できないため、より悪質な問題である。リスクは単なる不正確さではなく、予測不可能で構造的に誘発される不正確さなのである。
第5章:緩和戦略 I:訓練不要およびコンテキストエンジニアリング技術
このセクションでは、モデルの再訓練を必要とせず、推論時に実装可能な戦略、特にコンテキスト自体を操作することに焦点を当てた手法を概説する。
5.1 コンテキストの並べ替えと再ランキング
最も直接的で、しばしば効果的な戦略である。モデルは冒頭と末尾に最も注意を払うため、開発者は検索された文書を再ランキングし、最も関連性の高いものをこれらの「スポットライト」位置に配置することができる 22。これは単純だが強力なヒューリスティックである 21。
5.2 プロンプト圧縮
並べ替えの代わりに、これらの技術は「中間」部分の長さを完全に短縮する。Selective-Context、LLMLingua、LongLLMLinguaのような手法は、より小規模なLLMやパープレキシティベースの指標を用いて、主要なLLMにコンテキストを送信する前に、重要度の低いトークンや文書を特定し、枝刈りする 2。
5.3 チャンキングと反復処理(マップリデュース)
このアプローチは、単一の長文コンテキストを避け、文書を管理しやすい小さなチャンクに分割する。LLMは各チャンクを独立して処理し(「マップ」ステップ)、その後、最終的なLLM呼び出しが全チャンクからの結果を統合する(「リデュース」ステップ)。BriefContextワークフローは、特に医療RAG向けに設計されたこの戦略の代表例である 16。
5.4 戦略的なクエリ配置
いくつかの研究では、クエリを冒頭に置くだけでなく、コンテキストの末尾で繰り返す効果も探求されている。これは合成キー・バリュータスクでは完璧に機能したが、より複雑なMDQAタスクでは最小限の効果しか示さなかった 8。
これらの訓練不要な手法は、本質的にモデルのアーキテクチャ上のバイアスを固定の制約として扱う「回避策」である。これらは根本的な問題を解決するのではなく、モデルの偏ったアテンションパターンに合わせて入力を慎重にキュレーションすることで、問題を「管理」する。これは、プロンプトエンジニアリングを超えた新たな学問分野、しばしば「コンテキストエンジニアリング」と呼ばれるものの出現を示唆している 11。開発者がRAGアプリケーションでLITMを観測した際、基盤モデル(例:GPT-4)を再訓練することはできない。彼らが操作できる唯一のレバーは入力プロンプトである。モデルが冒頭と末尾を好むというバイアスを認識し 7、検索後に再ランキングステップを追加する。より単純なモデルやアルゴリズムを用いて文書の関連性をスコアリングし、プログラム的に上位1〜2の文書をコンテキスト文字列の最初や最後に配置し、関連性の低い文書を中間に挟む 39。これはモデルが中間を読む能力を向上させるのではなく、単に最も重要な情報が決して中間には来ないようにするだけである。これは、深いアーキテクチャ上の問題に対する、実用的なエンジニアリングソリューションと言える。
第6章:緩和戦略 II:アーキテクチャ革新とファインチューニングパラダイム
このセクションでは、LITMの根本原因に直接対処するために、モデルのアーキテクチャや訓練プロセス自体を変更する、より根本的な解決策を探る。
6.1 位置エンコーディングの修正
- 多重スケール位置エンコーディング(Multi-scale Positional Encoding, Ms-PoE): ファインチューニングを必要としない「プラグアンドプレイ」のアプローチ。この手法は、異なるアテンションヘッドが位置に対して異なる感度を持つことを認識する。Ms-PoEは、異なるヘッドに異なるRoPEのスケーリング比率を適用し、一部のヘッドが短距離のコンテキストに、他のヘッドが長距離のコンテキストに集中できるようにする。これにより、中間にある情報を「見つけ出す」のに役立つ多重スケールの視点が生まれる 41。
- 線形バイアス付きアテンション(Attention with Linear Biases, ALiBi): RoPEの代替案で、トークンに位置埋め込みを追加しない。代わりに、トークン間の距離に比例するペナルティをアテンションスコアに加える。これにより、近接するトークンに対する自然なバイアスが生まれ、標準的なPEよりも長いシーケンスへの優れた外挿能力を示すことが確認されている 10。
6.2 高度なファインチューニング手法
- 情報集約型訓練(INformation-INtensive, IN2)トレーニング: データ駆動型の解決策。研究者らは、答えが意図的に中間を含む様々な位置に配置された、大規模な合成長文コンテキストQAペアのデータセットを作成する。このデータセットでモデル(例:Mistral-7BをファインチューニングしてFILM-7Bを作成)を訓練することにより、モデルに位置バイアスを克服し、コンテキスト内のどこからでも情報を見つけ出すよう明示的に教える 41。
- 対照学習(Contrastive Learning): 新しいファインチューニング手法で、モデルが完全な長文コンテキストを与えられた場合と、最も関連性の高いサブコンテキスト(ヘルパーモデルによって検索されたもの)のみを与えられた場合で、類似した出力を生成するように訓練される。これにより、モデルは長文コンテキストの重要な部分に「集中」することを学習し、効果的に自身の内部検索を実行する方法を身につける 76。
6.3 進化するアテンションメカニズム
- 初期のスパースアテンションの限界: LongformerやBigBirdのようなモデルは、アテンションの$O(n^2)$計算量を克服するための初期の試みであった。これらは固定のスパースアテンションパターン(例:局所的なウィンドウアテンションと特定のトークンに対するグローバルアテンションの組み合わせ)を使用した 35。しかし、これらの固定パターンは硬直的すぎ、事前に定義されたパターン内に収まらない重要な長距離依存関係を見逃す可能性があり、独自のバージョンのLITMを生み出す可能性がある 35。
- 現代的アプローチ(StreamingLLM, Ring Attention): より最近のアーキテクチャは、さらなる効率性と堅牢性を目指している。StreamingLLMは、「アテンションシンク」(最初の数トークン)を用いて安定性を維持しつつ、スライディングウィンドウでコンテキストをストリームとして処理するが、依然として情報を失う可能性がある 81。Ring Attentionは分散環境向けに設計されており、シーケンスを「リング」として扱うことで、複数のデバイスにわたる計算の並列化を可能にし、極めて長いシーケンスを処理する 82。これらは、より根本的にスケーラブルなアテンションメカニズムを構築する最前線を示している。
これらの緩和戦略には、根本的な思想的対立が見られる。一方の陣営(例:Ms-PoE、ALiBi)は、既存のアテンションフレームワーク内で位置シグナルを改善することに焦点を当て、モデルが物事の「場所」をより簡単に知ることができるようにする。もう一方の陣営(例:IN2トレーニング)は、データを通じてモデルの検索能力を向上させることに焦点を当て、位置に関係なく情報を「見つける方法」を教える。最も堅牢な未来のソリューションは、おそらく両方の組み合わせを必要とするだろう。つまり、より優れた「GPS」(位置エンコーディング)と、より優れた「運転技術」(データ駆動型トレーニング)の両方である。
第7章:主要LLMの比較ベンチマーク分析
このセクションでは、最新の性能データを統合し、現行世代のフラッグシップモデルがLITM問題に関してどの位置にいるのかを明確に示す。
7.1 「Needle in a Haystack」(NIAH)における性能
- Gemini 1.5 Pro: テキスト、音声、動画の各モダリティにおいて、最大100万トークン以上のコンテキストでほぼ完璧(99%以上)なリコールを実証している。その性能は非常に堅牢で、この広大なコンテキスト内で針の位置に関わらず、ほとんど性能低下を示さない 4。
- Claude 3 Opus: 同様に、最大20万トークンのコンテキストウィンドウ内でほぼ完璧(99%以上)なリコールを示す。Anthropic社は、いくつかのケースで、モデルが「針」が「干し草の山」の中で場違いに見えることを指摘し、テストの人工的な性質自体を認識したと報告している 30。
- GPT-4シリーズ(Turbo/o): 一般的に、短いコンテキスト長では非常に良好な性能を示すが、コンテキストが長くなるにつれて、特に約7万トークンを超えると顕著な性能低下が見られる。古典的なU字型の曲線がより明確に現れ、針が文書の深さ7%から50%の間に配置された場合にリコールが大幅に低下する 27。
| モデル | 最大コンテキストウィンドウ(トークン) | NIAH性能 @ ~32K | NIAH性能 @ ~128K | NIAH性能 @ >200K | 既知の性能低下点 | 質的注記 |
| GPT-4o / Turbo | 128K | 高 | 中〜高 | N/A | 約73Kトークン以上で低下開始 | 明確なU字型曲線を示す |
| Claude 3 Opus | 200K | ほぼ完璧 (>99%) | ほぼ完璧 (>99%) | ほぼ完璧 (>99%) | 観測されず | テストの人工性を認識する場合がある |
| Gemini 1.5 Pro | 1M (最大10M) | ほぼ完璧 (>99%) | ほぼ完璧 (>99%) | ほぼ完璧 (>99%) | 観測されず | 複数モダリティで一貫して高い性能 |
| Llama-3.1-405b | 128K | 高 | 中 | N/A | 32Kトークン以上で低下開始(RAG設定) | オープンソースモデルの中で高い性能 |
7.2 NIAHを超えて:より複雑なベンチマークにおける性能
NIAHのスコアは高いものの、推論と統合を必要とするベンチマークでの性能は異なる様相を呈する。
- NoLiMaベンチマーク: このベンチマークは、単純な字句マッチングを防ぐように設計されている。このより困難なタスクでは、GPT-4oのようなトップモデルでさえ、ほぼ完璧なベースラインから正解率が約70%まで急落し、全てのモデルでわずか32Kのコンテキストで大幅な低下が見られる 28。
- 長文生成ベンチマーク(例:LongGenBench): これらのタスクは、長文コンテキストに基づいて長く、一貫性のある出力を生成することを要求する。ここでは、Gemini-1.5-FlashやGPT-4oを含むほとんど全てのモデルが、短いコンテキストでのベースライン能力と比較して大幅な性能低下を示す 82。
- 複数文書推論(例:SummHay, Loong): 多くの関連文書から情報を統合する必要があるタスクでは、GPT-4oやClaude 3 Opusのようなモデルは、リトリーバーなしでは非常に低いスコアしか記録せず、真の複数文書推論をネイティブに処理する能力がまだ不足していることを示している 1。
7.3 失敗モードの分析
コンテキストがストレス下に置かれたとき、異なるモデルは異なる方法で失敗する。例えば、Claude-3-sonnetのような旧世代のモデルは、著作権の懸念を理由に回答を拒否し始めることがあり、一方でDBRXは質問に答える代わりにコンテキストを要約するだけになることがある 5。これは、長文コンテキストの訓練がまだ未熟であり、予測不可能な振る舞いにつながる可能性があることを示唆している。
現在の長文コンテキストモデルの状態は、能力の明確な階層を反映している:リコール > 検索 > 推論。モデルは、長文コンテキストから文字通りの文字列を想起すること(NIAH)には非常に優れている。ある程度の意味的理解を必要とする情報を検索すること(NoLiMa)には、そこそこ優れている。しかし、長文コンテキストに散在する情報に基づいて推論し、統合し、生成すること(LongGenBench, Loong)は、依然として非常に不得手である。市場のナラティブは第一の能力に集中しているが、真の企業価値は第三の能力にある。Gemini 1.5 ProのNIAHでの結果は 4、それがほぼ完璧な「ポインタ」メカニズムを持っていることを示唆しており、これは解決済みの
探索問題である。NoLiMaの結果は 28、クエリと答えの間に意味的な推論が必要な場合、タスクがはるかに難しくなることを示しており、これはより困難な
検索問題である。LongGenBenchとLoongの結果は 33、複数の情報を統合して新しい結論を導き出すタスクではモデルが大きく失敗することを示しており、これは
理解と推論の問題である。したがって、LITM現象は一枚岩の問題ではない。単純なリコールについては大部分が解決されたが、複雑な推論については依然として巨大な課題として残っている。開発者は、アプリケーションを設計する際にこの能力の階層を認識する必要がある。
第8章:今後の方向性と結論
この最終セクションでは、本レポートの調査結果を統合し、より広範な戦略的展望について議論し、実用的な提言を提供する。
8.1 LLMサービングにおける「CAP原則」
LLMサービングのために提案されたCAP(Context, Accuracy, Performance)原則を紹介する 88。この定理は、いかなる最適化も、これら3つの相反する目標のうち最大2つまでしか改善できないと仮定する。例えば、コンテキスト長(C)と正解率(A)を向上させることは、計算負荷の増大により、しばしば性能(P)を犠牲にする。これは、長文コンテキストモデルをデプロイする際に伴うトレードオフを理解するための重要な戦略的フレームワークを提供する。
8.2 均一なコンテキスト利用への道
究極の目標は、U字型の性能曲線を、情報の位置に関係なく等しく評価される平坦な曲線へと変えることである。これには、本レポートで議論された戦略の統合が必要となるだろう。
- より堅牢で、バイアスの少ない位置エンコーディング。
- 位置不変性を明示的に教えるためのIN2のようなデータ中心の訓練アプローチ。
- コンテキストの情報密度に適応できる、より効率的で動的なアテンションメカニズム。
8.3 開発者向けベストプラクティスの要約
現在の最先端技術に基づき、実務家向けの簡潔な推奨事項リストを以下に提供する。
| 戦略 | カテゴリ | 主要メカニズム | 利点 | 欠点・限界 |
| コンテキスト再ランキング | プロンプト/コンテキストエンジニアリング | 最も関連性の高い文書を冒頭/末尾に配置 | 訓練不要、実装が容易 | 回避策であり根本原因は未解決 |
| IN2トレーニング | ファインチューニング | 様々な位置に答えがある合成データで訓練 | モデルの能力を根本的に向上 | 計算コストが高く、大規模データセットが必要 |
| Ms-PoE | アーキテクチャ/推論時 | 異なるアテンションヘッドに異なるRoPEスケーリング比率を適用 | ファインチューニング不要、プラグアンドプレイ | ヒューリスティックであり、全てのモデル/タスクに最適とは限らない |
| チャンキング/マップリデュース | プロンプト/コンテキストエンジニアリング | 文書を分割して個別に処理し、結果を統合 | 複雑な推論に強い、単一の長文コンテキストを回避 | レイテンシが増加する可能性、統合ステップが困難な場合がある |
| プロンプト圧縮 | プロンプト/コンテキストエンジニアリング | コンテキストから重要度の低いトークンを枝刈り | トークン数を削減し、コストとレイテンシを改善 | 重要な情報が誤って削除されるリスク |
- バイアスを前提とする: 均一なコンテキスト利用を前提としないこと。常に特定のユースケースで位置バイアスをテストすること。
- デフォルトで再ランキングする: RAGアプリケーションでは、最も重要な情報をコンテキストの冒頭または末尾に配置するための再ランキングステップを実装すること。
- 複雑な推論ではチャンク化する: タスクが文書の複数の離れた部分からの情報統合を必要とする場合、単一の長文コンテキスト呼び出しよりも、マップリデュース/チャンキング戦略の方が信頼性が高い可能性が高い。
- 適切なベンチマークを選択する: NIAHだけに依存しないこと。実際のタスク(例:推論、要約)を反映したベンチマークを使用または作成し、真の性能を測定すること。
8.4 結論
「Lost in the Middle」現象は、LLMが単純なテキストプロセッサから真の推論エンジンへと移行する過程で直面する極めて重要な課題である。特に純粋なリコール能力においては大きな進歩が見られたものの、真の長文コンテキスト理解への道のりはまだ始まったばかりである。このハードルを乗り越えることが、次世代のAIアプリケーションの可能性を解き放つ鍵となるだろう。
引用文献
- Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems – ACL Anthology https://aclanthology.org/2024.emnlp-main.552.pdf
- Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach – arXiv https://arxiv.org/html/2407.16833v1
- Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems – arXiv https://arxiv.org/html/2407.01370v1
- Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context – arXiv https://arxiv.org/pdf/2403.05530
- Long Context RAG Performance of LLMs | Databricks Blog https://www.databricks.com/blog/long-context-rag-performance-llms
- Michelangelo: Long Context Evaluations Beyond Haystacks via Latent Structure Queries https://arxiv.org/html/2409.12640v2
- Lost in the Middle: How Language Models Use Long … – CS Stanford https://cs.stanford.edu/~nfliu/papers/lost-in-the-middle.tacl2023.pdf
- Lost in the Middle: How Language Models Use Long Contexts Paper Reading – Arize AI https://arize.com/blog/lost-in-the-middle-how-language-models-use-long-contexts-paper-reading/
- Long Context LLMs — A Game Changer | by Adrien Riaux | Medium https://medium.com/@adrien.riaux/long-context-llms-a-game-changer-300e423736d5
- Beyond the Limits: A Survey of Techniques to Extend the Context Length in Large Language Models – arXiv https://arxiv.org/html/2402.02244v3
- Context Engineering Has Arrived | cbarkinozer | Medium https://cbarkinozer.medium.com/context-engineering-has-arrived-9dab97805d0a
- Understanding LLM Context Windows: Tokens, Attention, and Challenges | by Tahir | Medium https://medium.com/@tahirbalarabe2/understanding-llm-context-windows-tokens-attention-and-challenges-c98e140f174d
- Lost in the Middle: How Language Models Use Long Contexts – ACL Anthology https://aclanthology.org/2024.tacl-1.9/
- Lost in the Middle: How Language Models Use Long Contexts – ResearchGate https://www.researchgate.net/publication/372162904_Lost_in_the_Middle_How_Language_Models_Use_Long_Contexts
- The NLP Task Effectiveness of Long-Range Transformers – ResearchGate https://www.researchgate.net/publication/373815792_The_NLP_Task_Effectiveness_of_Long-Range_Transformers
- Leveraging long context in retrieval augmented language models for medical question answering – PMC https://pmc.ncbi.nlm.nih.gov/articles/PMC12048518/
- 【LLM/生成AI】言語モデルの長文コンテキスト処理とLost in the Middle現象について – Zenn https://zenn.dev/manase/scraps/aaea7204c38ed6
- 気まぐれAI攻略法|プロンプト・テイミングの実践術 – Arpable https://arpable.com/artificial-intelligence/prompt-taming-ai-conversation-guide/
- Lost in the Middle: How Language Models Use Long Contexts – MIT Press Direct https://direct.mit.edu/tacl/article/doi/10.1162/tacl_a_00638/119630/Lost-in-the-Middle-How-Language-Models-Use-Long
- How Language Models Use Long Contexts (LLM)? – YouTube https://www.youtube.com/watch?v=3iH6E-YgRPc
- AIの現状の限界を理解する:「Lost in the Middle」と「ポチョムキン … https://note.com/just_50/n/n1fdfb62ce3f4
- Lost in the middle: a deep dive – by Greg Paul – Medium https://medium.com/@_andgreg/lost-in-the-middle-a-deep-dive-b168c862e71f
- Lost in the Middle: How Language Models use Long Context – Explained! – YouTube https://www.youtube.com/watch?v=Kf3LeaUGwlg
- The Needle In a Haystack Test | Towards Data Science https://towardsdatascience.com/the-needle-in-a-haystack-test-a94974c1ad38/
- gkamradt/LLMTest_NeedleInAHaystack: Doing simple retrieval from LLM models at various context lengths to measure accuracy – GitHub https://github.com/gkamradt/LLMTest_NeedleInAHaystack
- Understanding the RoPE Extensions of Long-Context LLMs: An Attention Perspective – ACL Anthology https://aclanthology.org/2025.coling-main.600.pdf
- Long context models in the enterprise: benchmarks and beyond – Snorkel AI https://snorkel.ai/blog/long-context-models-in-the-enterprise-benchmarks-and-beyond/
- NoLiMa: Long-Context Evaluation Beyond Literal Matching – arXiv https://arxiv.org/html/2502.05167v2
- Counting-Stars ( ): A Multi-evidence, Position-aware, and Scalable Benchmark for Evaluating Long-Context Large Language Models – arXiv https://arxiv.org/html/2403.11802v5
- Introducing the next generation of Claude – Anthropic https://www.anthropic.com/news/claude-3-family
- Gemini 1.5: Unlocking multimodal understanding … – Googleapis.com https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
- NoLiMa: Long-Context Evaluation Beyond Literal Matching – Finally a good benchmark that shows just how bad LLM performance is at long context. Massive drop at just 32k context for all models. – Reddit https://www.reddit.com/r/LocalLLaMA/comments/1io3hn2/nolima_longcontext_evaluation_beyond_literal/
- Leave No Document Behind: Benchmarking Long-Context LLMs with Extended Multi-Doc QA – ACL Anthology https://aclanthology.org/2024.emnlp-main.322.pdf
- Attention Mechanism in LLMs: An Intuitive Explanation – DataCamp https://www.datacamp.com/blog/attention-mechanism-in-llms-intuition
- Core Context Aware Transformers for Long Context Language Modeling – ICML 2025 https://icml.cc/virtual/2025/poster/45555
- HDT: Hierarchical Document Transformer – Andreas Geiger https://www.cvlibs.net/publications/He2024COLM.pdf
- Daily Papers – Hugging Face https://huggingface.co/papers?q=Sparse%20Attention
- Beyond Attention: Breaking the Limits of Transformer Context Length with Recurrent Memory https://ojs.aaai.org/index.php/AAAI/article/view/29722/31239
- 言語モデルの長文コンテキスト処理:「Lost in the Middle」現象の … https://zenn.dev/kimkiyong/articles/c0250864d53595
- Dynamic Asymmetric Attention for Enhanced Reasoning and Interpretability in LLMs – MDPI https://www.mdpi.com/2073-8994/17/8/1303
- Mitigate Position Bias in LLMs via Scaling a Single Hidden States Channel – arXiv https://arxiv.org/html/2406.02536v3
- Mitigate Position Bias in Large Language Models via Scaling a Single Dimension – arXiv https://arxiv.org/html/2406.02536v2
- Mitigate Position Bias in Large Language Models via Scaling a Single Dimension | Request PDF – ResearchGate https://www.researchgate.net/publication/381158424_Mitigate_Position_Bias_in_Large_Language_Models_via_Scaling_a_Single_Dimension
- Mitigate Position Bias in Large Language Models via Scaling a Single Dimension – OpenReview https://openreview.net/pdf/8ad0177f303a68095d1b7b366e4697578570cbef.pdf
- A Gentle Introduction to Positional Encoding in Transformer Models, Part 1 – MachineLearningMastery.com https://machinelearningmastery.com/a-gentle-introduction-to-positional-encoding-in-transformer-models-part-1/
- Positional Encoding Explained: A Deep Dive into Transformer PE – Medium https://medium.com/thedeephub/positional-encoding-explained-a-deep-dive-into-transformer-pe-65cfe8cfe10b
- Beyond Attention: How Advanced Positional Embedding Methods Improve upon the Original Approach in Transformer Architecture | by Elahe Aghapour | TDS Archive | Medium https://medium.com/data-science/beyond-attention-how-advanced-positional-embedding-methods-improve-upon-the-original-transformers-90380b74d324
- The Impact of Positional Encoding on Length Generalization in Transformers – arXiv https://arxiv.org/pdf/2305.19466
- Found in the Middle: How Language Models Use Long Contexts Better via Plug-and-Play Positional Encoding – NIPS https://proceedings.neurips.cc/paper_files/paper/2024/file/6ffdbbe354893979367f93e2121e37dd-Paper-Conference.pdf
- Found in the Middle: How Language Models Use Long Contexts Better via Plug-and-Play Positional Encoding – OpenReview https://openreview.net/pdf?id=fPmScVB1Td
- Mitigate Position Bias in LLMs via Scaling a Single Hidden States Channel – ACL Anthology https://aclanthology.org/2025.findings-acl.316.pdf
- Retrieval Augmented Generation (RAG) for LLMs – Prompt Engineering Guide https://www.promptingguide.ai/research/rag
- Characterizing Prompt Compression Methods for Long Context Inference – arXiv https://arxiv.org/html/2407.08892v1
- LLMとの会話で感じる違和感の正体:「ロストインコンバセーション」現象のナゾに迫る! https://www.ecomottblog.com/?p=17769
- Long-Context LLMs Meet RAG: Overcoming Challenges for Long Inputs in RAG | OpenReview https://openreview.net/forum?id=oU3tpaR8fm¬eId=8X6xAgSGa2
- Long-Context LLMs Meet RAG: Overcoming Challenges for Long Inputs in RAG – arXiv https://arxiv.org/html/2410.05983v1
- Attention Basin: Why Contextual Position Matters in Large Language Models – arXiv https://arxiv.org/html/2508.05128v1
- Claude 3 Opus vs GPT-4: Task Specific Analysis – Vellum AI https://www.vellum.ai/blog/claude-3-opus-vs-gpt4-task-specific-analysis
- Your Guide to Context Engineering: The Four‑Pillar Blueprint Replacing Prompt Engineering for Scalable, Memory‑Savvy AI | by Manish Ghoshal | Jul, 2025 | Medium https://medium.com/@manishghoshal99.py/your-guide-to-context-engineering-the-four-pillar-blueprint-replacing-prompt-engineering-for-6c1dc4ed8fba
- A Survey of Context Engineering for Large Language Models – arXiv https://arxiv.org/html/2507.13334v1
- [2403.04797] Found in the Middle: How Language Models Use Long Contexts Better via Plug-and-Play Positional Encoding – arXiv https://arxiv.org/abs/2403.04797
- Found in the Middle: How Language Models Use Long Contexts Better via Plug-and-Play Positional Encoding – arXiv https://arxiv.org/html/2403.04797v1
- NeurIPS Poster Found in the Middle: How Language Models Use Long Contexts Better via Plug-and-Play Positional Encoding https://neurips.cc/virtual/2024/poster/94207
- Xiaoxia Wu – CatalyzeX https://www.catalyzex.com/author/Xiaoxia%20Wu
- Found in the Middle: How Language Models Use Long Contexts Better via Plug-and-Play Positional Encoding | OpenReview https://openreview.net/forum?id=fPmScVB1Td&referrer=%5Bthe%20profile%20of%20Shiwei%20Liu%5D(%2Fprofile%3Fid%3D~Shiwei_Liu2)
- Found in the Middle: How Language Models Use Long Contexts https://www.alphaxiv.org/overview/2403.04797v1
- Found in the Middle: How Language Models Use Long … – arXiv https://arxiv.org/pdf/2403.04797
- Beyond the Limits: A Survey of Techniques to Extend the Context Length in Large Language Models – IJCAI https://www.ijcai.org/proceedings/2024/0917.pdf
- Sliding Window Attention Training for Efficient Large Language Models – arXiv https://arxiv.org/html/2502.18845v1
- Daily Papers – Hugging Face https://huggingface.co/papers?q=Attention%20with%20Linear%20Biases%20(ALiBi)
- Make Your LLM Fully Utilize the Context | OpenReview https://openreview.net/forum?id=YGTVEmBXtV
- Make Your LLM Fully Utilize the Context – arXiv https://arxiv.org/html/2404.16811v1
- Make Your LLM Fully Utilize the Context https://neurips.cc/media/neurips-2024/Slides/94709.pdf
- [2404.16811] Make Your LLM Fully Utilize the Context – arXiv https://arxiv.org/abs/2404.16811
- Make Your LLM Fully Utilize the Context – OpenReview https://openreview.net/pdf?id=YGTVEmBXtV
- Reducing Distraction in Long-Context Language Models by Focused Learning – arXiv https://arxiv.org/html/2411.05928v1
- Incremental accumulation of linguistic context in artificial and biological neural networks https://pmc.ncbi.nlm.nih.gov/articles/PMC11748659/
- Curse of High Dimensionality Issue in Transformer for Long-context Modeling – arXiv https://arxiv.org/html/2505.22107v4
- CORE CONTEXT AWARE ATTENTION FOR LONG CON- TEXT LANGUAGE MODELING – OpenReview https://openreview.net/pdf?id=6yzsKPWzwt
- Track: Oral Session 1A – ICLR 2026 https://iclr.cc/virtual/2025/session/31935
- Efficient Streaming Language Models with Attention Sinks – OpenReview https://openreview.net/forum?id=NG7sS51zVF
- LONGGENBENCH: Long-context Generation Benchmark – ACL Anthology https://aclanthology.org/2024.findings-emnlp.48.pdf
- EUREKA: Evaluating and Understanding Large Foundation Models – Microsoft https://www.microsoft.com/en-us/research/wp-content/uploads/2024/09/Eureka-Evaluating-and-Understanding-Large-Foundation-Models-Sept-13.pdf
- Unlocking precision: The “Needle-in-a-Haystack” test for LLM evaluation – Labelbox https://labelbox.com/guides/unlocking-precision-the-needle-in-a-haystack-test-for-llm-evaluation/
- What Makes Anthropic’s Claude 3 Special http://stonecroftfolk.com/index-1805.html
- LongGenBench: Benchmarking Long-Form Generation in Long Context LLMs | OpenReview https://openreview.net/forum?id=3A71qNKWAS
- LongGenbench: Benchmarking Long-Form Generation in Long Context LLMs – arXiv https://arxiv.org/html/2409.02076v6
- The CAP Principle for LLM Serving: A Survey of Long-Context Large Language Model Serving – arXiv https://arxiv.org/html/2405.11299v2
- The CAP Principle for LLM Serving: A Survey of Long-Context Large Language Model Serving – arXiv https://arxiv.org/pdf/2405.11299

