第1章:パーソナルナレッジベースの構築:キュレーションによるグラウンディングの原則
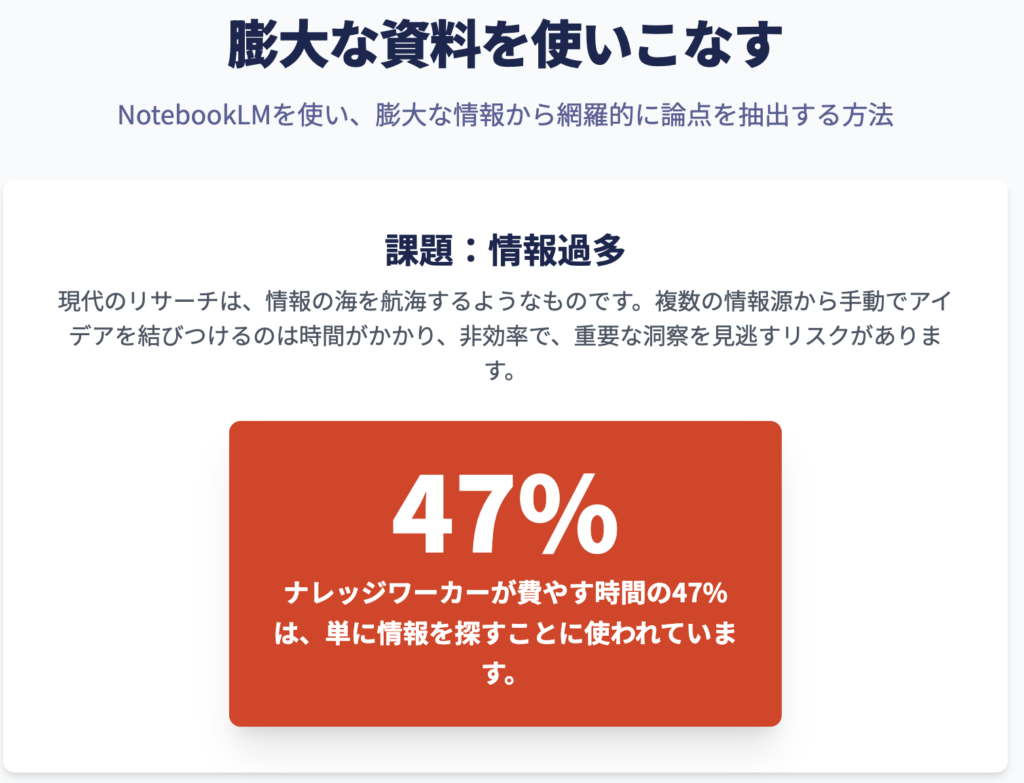
GoogleのNotebookLMを活用した高度な分析作業の成否は、最初のステップ、すなわち情報源(ソース)の選定と構築にかかっている。このツールは、ユーザーが提供した資料のみを知識の源泉とする「グラウンディング(接地)」という基本原則に基づいて動作する 1。したがって、論点抽出のプロセスは、単なるファイルのアップロード作業ではなく、信頼性の高い専用のナレッジベースを意図的に「構築」する知的作業として捉える必要がある。本章では、その基盤となる考え方と具体的な戦略について詳述する。
1.1. パラダイムシフト:検索エンジンからキュレーションされた宇宙へ
一般的な大規模言語モデル(LLM)がインターネット上の広範なデータから応答を生成するのに対し、NotebookLMは根本的に異なるアプローチを採用している。その知識は、ユーザーが特定の「ノートブック」にアップロードした資料群に完全に限定される 。この構造は、AIの思考範囲をユーザーが定義した「キュレーションされた宇宙(curated universe)」内に閉じ込めることを意味する。
この「グラウンディング」こそが、他のAIツールで頻繁に見られる、根拠のない情報を生成する「ハルシネーション(幻覚)」を抑制する主要なメカニズムである 2。AIの認識する現実は、ユーザーが選んだ資料によって完全に規定される。このパラダイムシフトは、ユーザーの役割を単なる「質問者」から「AIのナレッジベースの設計者」へと変貌させる。つまり、分析の質は、プロンプトエンジニアリングの技術以上に、ユーザーの資料選定能力、すなわちキュレーションのスキルに直接的に依存することになる。
このモデルでは、分析の信頼性、関連性、そしてバイアスの有無に対する責任は、全面的にユーザーに委ねられる。したがって、NotebookLMを効果的に活用するための最も重要なフェーズは、最初の質問を入力する前の、資料を吟味し、整理し、戦略的に配置する段階にある。研究者は、司書やアーキビストのように、分析の土台となるテキストを慎重に選び抜くという思考法を持つことが求められる。
1.2. 戦略的なソースの選定と準備
NotebookLMは、多様な形式の資料をソースとして受け入れる柔軟性を持つ。具体的には、Google Drive上のファイル(ドキュメント、スライド)、PDF、テキストファイル、コピー&ペーストしたテキスト、ウェブサイトのURL、さらにはYouTube動画(文字起こしを解析)まで対応している 1。また、PDFやスライド内に含まれる画像、グラフ、図表の内容についても質問が可能であり、マルチモーダルなナレッジベースの構築を支援する 7。
しかし、この柔軟性は品質の重要性を決して低減させない。特にPDFファイルの場合、その有効性はテキストデータが適切に埋め込まれているかどうかにかかっている。スキャンされただけの画像ベースのPDFは、AIにとっては実質的に空白のページと変わらないため、事前にOCR(光学的文字認識)処理を施し、テキストレイヤーを生成しておくことが不可欠である 5。
専門的な分析ワークフローにおいては、「ソース」は単なるファイルではなく、構造化された「証拠」として扱われるべきである。準備段階では、技術的な可読性を確保する(OCR処理など)だけでなく、分析の焦点を明確にするための戦略的な取捨選択が求められる。これは一種の「データクリーニング」の思考法である。例えば、数百ページに及ぶ年次報告書を分析する際、付録や定型的な免責事項を除外し、本質的な分析部分のみを抽出したバージョンを作成することで、AIの注意を重要な情報に集中させることができる。
このように、専門家はファイルをそのままアップロードするのではなく、分析用に「準備」する。OCR処理の実行、長大な文書の章ごとの分割、あるいは最重要箇所のみを抜粋した新しいテキストファイルの作成といった手間をかけることで、AIが分析する情報源を極めて高密度で「シグナルリッチ」なものへと昇華させることができる。このアプローチは、ユーザーが直面する「膨大な資料」という課題に対し、それを管理し、焦点を絞るための具体的な戦略を提供する。
1.3. 運用上の制約の理解:戦略的ガイドとしての制限
NotebookLMの利用には、いくつかの運用上の制限が存在する。これらの制限は、技術的な障壁としてではなく、研究設計を導くための戦略的な指針として捉えるべきである。
主要な制限は以下の通りである(注:情報は更新される可能性があり、公式ヘルプが最新の情報源となる):
- ノートブックあたりのソース数: 最大50個 8
- ソースあたりの単語数: 最大500,000語 8
- ファイルサイズ上限: 1ファイルあたり200 MB 8
- ユーザーあたりのノートブック数: 最大100個 10
例えば、300 MBのデータセットは直接アップロードできないため、分割や情報の精査が必要となる 9。この制約は、ユーザーに対して「どのように分割するか?」という戦略的な問いを投げかける。時系列、テーマ別、あるいはサブトピック別など、分割の方法そのものが分析のアプローチを規定する。
これらの制限は、結果としてモジュール型のアプローチを推奨する。一つの巨大なプロジェクトに対して単一のモノリシックなノートブックを作成するのではなく、テーマごとに焦点を絞った複数のノートブックを構築することが賢明である。例えば、「市場分析レポート」用のノートブック、「社内戦略メモ」用のノートブック、「競合他社のプレスリリース」用のノートブック、といった具合に分割する。
このセグメンテーションにより、各ノートブック内でのAIのタスクはより限定的かつ明確になり、生成される回答の精度も向上する。例えば、「市場分析レポート」のノートブック内で「第1四半期の収益トレンドを要約せよ」といった具体的な質問を行った後、各ノートブックから得られた主要な知見をエクスポートし、最終的にそれらを統合する「マスター統合ノートブック」で全体の統合分析を行うことができる。このように、制約を戦略的に活用することで、分析プロセス全体の質を高めることが可能となる。
第2章:体系的尋問フレームワーク:論点抽出のための多段階アプローチ
キュレーションされたナレッジベースを構築した後、次に行うのは、その知識を体系的に引き出すための対話プロセスである。このプロセスは、場当たり的な質問の繰り返しであってはならない。網羅的な論点抽出を実現するためには、広範な探索から始まり、徐々に詳細な分析へと移行する、構造化され、再現可能な一連のフェーズを経る必要がある。本章では、そのための多段階アプローチ「体系的尋問フレームワーク」を提示する。
2.1. フェーズ1:自動偵察とテーマのマッピング
資料をノートブックにアップロードすると、NotebookLMは即座に自動分析を開始し、その結果を複数の形式で提示する。この初期段階は、詳細な分析に入る前の「偵察フェーズ」と位置づけられる。
- ソースガイド(Source Guide): 各ソースの要約、主要なトピック、そしてAIが提案する質問候補が自動的に生成される 5。これは、資料群の全体像を迅速に把握するための最初の羅針盤となる。
- マインドマップ(Mind Map): 主要なトピックとそれらの関連性を視覚的な分岐図として表示する機能である 12。複雑な情報の構造を直感的に理解し、個々の資料を読むだけでは気づきにくいトピック間の隠れたつながりを発見するのに役立つ。
このフェーズの目的は、自身のソースキュレーションが適切であったかを検証し、初期の仮説を形成することにある。自動生成された要約は、自身の資料に対する理解と一致しているか?提案された質問は、予期せぬ分析の切り口を示唆していないか?特にマインドマップは、単なる要約ツールではなく、仮説生成ツールとして極めて強力である。例えば、二つの予期せぬトピックがマインドマップ上で強く結びついていることを発見した場合、その関連性の探求が、次のフェーズにおける最初の重要な問いとなる。
この偵察フェーズを経ることで、分析者は「この資料には何が書かれているか?」という漠然とした問いから、「これらの資料は、AというテーマとBというテーマの間に予期せぬ関連性があることを示唆している。その関連性の本質は何か?」という、より鋭く、焦点を絞った問いへと移行することができる。
2.2. フェーズ2:広範なテーマの抽出
偵察フェーズで全体像を把握した後、ナレッジベースの根幹をなす主要な論点やデータを体系的に抽出する。このフェーズでは、具体的でありながらも、資料群全体を横断するようなオープンエンドな質問を投げかけることが中心となる。
この段階で効果的なプロンプトは、「この資料について教えて」といった曖昧なものではなく、「この資料における主要な3つの論点は何か」といった具体的な指示を含むものである 5。さらに、出力を特定の形式(例:FAQ、学習ガイド、箇条書き)で要求することで、抽出した情報を初期段階から構造化することが可能になる 7。
このフェーズで用いるプロンプトの例:
- 「すべてのソースを横断して、[トピックX]に関する主要な主張を特定し、要約してください。」
- 「資料内で定義されているの定義をすべてリストアップし、それぞれの出典を明記してください。」
- 「[指標Z]に関連するすべての定量的データを抽出し、表形式で提示してください。」 15
- 「提供された従業員ハンドブックに基づいて、よくある質問(FAQ)を生成してください。」 14
このフェーズの鍵は、網羅性と具体性のバランスを取ることにある。「すべてを要約して」というプロンプトは効果が薄いが、「2023年の市場予測に関する各ソースの主要な結論を要約せよ」というプロンプトは極めて強力である。この段階は、資料群に含まれる中核的な主張と証拠を体系的に「棚卸し」する作業に他ならない。
2.3. フェーズ3:詳細な深掘り分析
主要なテーマの棚卸しが完了したら、次は個々の論点について、その詳細、根拠、そしてニュアンスを深く掘り下げるフェーズに入る。ここでは、分析の精度を高めるためのNotebookLMの重要な機能が活用される。
ソース名の横にあるチェックボックスをオン/オフすることで、AIの注意を特定のソースに限定したり、あるいは特定のソースを分析対象から除外したりすることができる 1。これにより、単一の重要な報告書や、特定の文書サブセットに対して、集中的な尋問を行うことが可能となる。
このフェーズで用いるプロンプトの例:
- (ソースAのみを選択した状態で)「この報告書の第3章において、著者の主張を裏付けるために引用されている主要な証拠は何ですか?」 15
- 「『プロジェクト・タイタン』に関する言及をすべて見つけ出し、それに関連する人物をリストアップしてください。」
- 「45ページに記載されている研究で用いられた方法論を説明してください。」
このソース選択機能は、分析における「精密機器」である。クエリごとに知識の「宇宙」を動的に再定義することを可能にする。これは、情報の意図しない混同を避ける上で極めて重要である。例えば、法的な契約書を分析する際には、その契約書のみを対象として質問を投げかける必要があり、ノートブック内の他の関連文書からの情報が混入することは避けなければならない。この機能は、法医学的なレベルでの分析的焦点を実現する。
2.4. フェーズ4:関係性の比較分析
このフレームワークにおける最も高度な段階が、複数のソースからの情報を統合し、新たな知見を生み出す「関係性の分析」である。ここでは、単なる情報の検索や要約を超え、情報と情報の「間」にある関係性を探求する。
このフェーズのプロンプトは、明確に比較や対照を指示するものとなる。「ソースAとソースBの共通点と相違点を説明せよ」 5 や、「同じトピックに関するこれら二つの報告書の結論を対比せよ」 16 といった問いが中心となる。
このフェーズで用いるプロンプトの例:
- (ソースAとソースCを選択した状態で)「これら二つの部門の戦略計画における、主要な意見の相違点は何ですか?」 16
- 「第1四半期から第4四半期までのこれらの議事録を通じて、『シナジー』という言葉の使われ方の変遷を追跡してください。」
- 「提供されたすべての研究論文に基づき、治療法Xの有効性に関するコンセンサスとしての結論は何ですか?」 5
- 「もし報告書Aの著者が報告書Bの方法論を批判するとしたら、その要点は何になるでしょうか?」 15
この段階において、NotebookLMは単なる検索・要約ツールから、真の「分析パートナー」へと昇華する。ユーザーは、ソースを慎重に選択し、比較的なプロンプトを巧みに用いることで、資料群の中に隠された対話、対立、そして合意を発見することができる。このプロセスは、個々の文書を単独で読むだけでは決して見えてこない、全体を貫く物語や、競合する複数の物語を明らかにする。これこそが、ユーザーの要求である「網羅的に論点を抽出する」ことを最も直接的に実現する方法である。なぜなら、それは個々の論点だけでなく、論点間の「議論」そのもの、すなわちデータセット全体にわたるアイデアの相互作用に焦点を当てるからである。
表1:プロンプト戦略マトリクス
以下の表は、体系的尋問フレームワークの各フェーズにおける目的と、それに最適化されたプロンプトの特性を整理したものである。これは、分析作業において適切な言語的ツールを意識的に選択するための実践的なガイドとなる。
| 分析フェーズ | 目的 | プロンプトの特性 | プロンプト例 | 関連ソース |
| フェーズ1:偵察 | 高レベルの概要把握、主要テーマと構造の特定 | 広範でオープンエンド。組み込み機能を活用。 | – 「マインドマップを生成して」 – 「このソースの要約を提供して」 – (自動生成された質問のレビュー) | 5 |
| フェーズ2:テーマ抽出 | 資料群全体の中核的な主張、定義、データを体系的に棚卸しする | 情報の「種類」は具体的だが、「範囲」は広範。出力形式を指定することが多い。 | – 「全ソースを対象に、[トピック]に関する上位3つの主張をリストアップして」 – 「これらの文書で定義されている主要用語の用語集を生成して」 – 「ソースで言及されている主要な出来事のタイムラインを作成して」 | 5 |
| フェーズ3:深掘り分析 | 限定された範囲内で、特定の証拠、詳細、文脈を調査する | 高度にターゲットを絞り、特定のソース、章、ページを参照。ソース選択機能を活用。 | – (ソースBを選択)「セクション4.2で説明されている方法論は何ですか?」 – 「この文書内の『プロジェクト・フェニックス』に関する言及をすべて見つけて」 – 「12ページのグラフの重要性を説明して」 | 1 |
| フェーズ4:関係性分析 | ソース間の比較、対照、接続を通じて新たな知見を統合する | 明確に比較・関係性を示す。「比較」「対照」「関係」「相違点」「変遷」などの言葉を使用。 | – 「報告書Aと報告書Bの結論を比較して」 – 「これら3つの記事におけるコンセンサスと意見の相違点は何ですか?」 – 「ソースCの視点は、ソースDでなされた仮定にどのように挑戦しますか?」 | 5 |
第3章:統合ワークベンチ:抽出から洞察への転換
体系的尋問フレームワークを通じて情報を抽出した後、次のステップは、それらの断片的な情報を整理し、注釈を加え、新たな洞察へと統合することである。NotebookLMのインターフェースは、この統合プロセスを支援するために設計されており、特に「ノート」機能がその中心的な役割を果たす。このセクションでは、「ノート」機能を分析の「ワークベンチ」として活用し、抽出した論点を洗練された知見へと昇華させるためのワークフローを詳述する。
3.1. 「ピン」と「ノート」のワークフロー:情報の捕捉と注釈
分析プロセス中、AIからの重要な回答やソース内の決定的な一節を発見した際、ユーザーは「ピン」アイコンをクリックすることで、その情報を画面右側の「ノート」エリアに保存できる 12。この「ピン留め」された情報に加えて、ユーザー自身の考察やメモを自由形式で書き加えることも可能である 7。
この一連の操作は、分析の素材を収集するための基本的なメカニズムである。尋問の各フェーズを進めながら、鍵となる発見、説得力のある引用、重要なデータポイントをすべてピン留めしていく。これにより、セッション全体から得られた最も価値のある情報のキュレーション済みコレクションが構築される。
しかし、このプロセスは単なる受動的なブックマーク作業ではない。「ノート」セクションは、能動的な「ワークベンチ」として扱われるべきである。ピン留めされた各項目には、ユーザー自身の注釈を付与することが極めて重要となる。「なぜこの情報をピン留めしたのか?」「その重要性は何か?」「他のピン留めされた項目とどのように関連するのか?」といった問いに対する答えを書き込むことで、生のデータは分析済みの情報へと転換される。これらのノートは、後からグループ化したり、階層的に整理したりすることも可能である 18。
3.2. 究極の統合テクニック:ノートを新たなソースに変換する
NotebookLMは、「すべてのノートをソースに変換する」という、極めて強力な統合機能を備えている 12。これは、ユーザーがピン留めした情報と自身の注釈からなる「ノート」セクション全体を、ノートブック内で利用可能な一つの新しいソースドキュメントに変換する機能である。
これは、このツールにおける最も高度な統合機能と言える。数時間にわたる尋問、ピン留め、そして注釈の末に、ユーザーは資料群全体に対する自身の統合された理解を体現する、高密度でキュレーション済みの新しい文書を創り出したことになる。
この機能は、再帰的かつ反復的な分析プロセスを可能にする。
統合ワークフローの例:
- ラウンド1分析: 元のソースドキュメント(報告書A、B、C)を尋問し、主要な発見をピン留めし、自身の分析的コメントを追加する。
- 統合: 「すべてのノートをソースに変換する」機能を使用し、新しいドキュメント「統合文書_v1」を作成する。
- ラウンド2分析: 元のソース(A、B、C)の選択を解除し、「統合文書_v1」のみを選択する。これにより、自分自身の発見物に対するメタ分析が可能になる。
- メタ分析プロンプトの例:
- 「この統合文書に基づき、全体を貫くテーマは何ですか?」
- 「これらのノート内に矛盾点があれば特定してください。」
- 「これらの主要な発見に基づいて、エグゼクティブサマリーを起草してください。」
このワークフローは、分析の抽象度を一段階引き上げることを可能にする。生のデータを分析する段階から、データに対する自身の「分析」を分析する段階へと移行するのである。これこそが、高レベルで新規性のある洞察を生成し、最終的な報告書や論文の草稿を作成するための鍵となる。それは、最も重要な論点のみで構成された文書を生成し、最終的な要約と構造化の準備を整えることで、ユーザーの「論点を抽出する」という要求に直接的に応えるものである。
第4章:分析的完全性の確保:リスク緩和と出力検証のフレームワーク
専門家レベルのガイドは、ツールの限界を厳格に評価し、信頼性の高い分析を保証するためのフレームワークを提供しなければならない。NotebookLMは強力なツールであるが、その出力を無批判に受け入れることは、分析の完全性を損なう危険を伴う。本章では、AIのハルシネーション、データセキュリティ、そして出力の検証ワークフローという、分析の信頼性を確保するための重要な要素に焦点を当てる。
4.1. グラウンディングされたシステムにおけるハルシネーションの理解
NotebookLMの最大の利点の一つは、そのアーキテクチャが本質的にハルシネーションのリスクを最小化する点にある。提供されたソースのみに基づいて回答を生成するため、一般的なチャットボットのように、インターネット上の情報から事実無根の情報を「発明」する可能性は極めて低い 2。
しかし、リスクがゼロというわけではない。AIは、曖昧なテキストを誤って解釈したり、不正確な推論を行ったり、あるいは不適切なプロンプトに対して情報を「創造的」に補完しようとしたりする可能性がある 20。NotebookLMにおけるハルシネーションは、無からの捏造というよりは、提供されたテキストの「誤読」や「過剰解釈」という形で現れる。その危険性はより巧妙であるが、同様に深刻である。
したがって、ユーザーのメンタルモデルは、「AIは嘘をついているか?」という問いから、「AIは提供されたテキストを正しく解釈しているか?」という問いへとシフトする必要がある。これは、問題を欺瞞から解釈学へと再定義するものであり、あらゆる定性的研究において馴染み深い課題である。ツールは批判的思考の必要性をなくすのではなく、その焦点をより鋭く、明確にするのである。
4.2. 検証ワークフロー:信頼、されど検証
NotebookLMが生成するすべての回答には、インライン引用が含まれている。これは、ソースドキュメント内の特定の箇所に対応する番号付きのリンクである 4。この引用番号をクリックすると、AIが回答を形成するために使用した正確なテキストが、元のソース上で即座にハイライト表示される 7。
この機能は、NotebookLMにおける分析的完全性の礎である。AIが生成する一つ一つの主張に対して、直接的で透明性の高い監査証跡(オーディット・トレイル)を提供する。
専門的なワークフローにおける譲れないステップは、主要な主張に対して、常にこの引用をチェックすることである。これは任意ではなく、必須のプロセスである。
検証プロセス:
- AIから回答を受け取る。
- 回答に含まれる中核的な主張を特定する。
- 各主張について、対応する引用番号(例:, )をクリックする。
- ハイライトされたソーステキストを自身で読む。
- 自問する:「このソーステキストは、AIの主張を本当に、そして明確に裏付けているか?」
このプロセスは、ユーザーを真実の最終的な裁定者として位置づける。AIの役割は、超人的な速さで関連情報を見つけ出し、関係性を提案する世界クラスのリサーチアシスタントである。一方、ユーザーの役割は、そのアシスタントの仕事を検証する上級研究員である。この「人間参加型(Human-in-the-Loop)」システムは、AIの速度と専門家の批判的判断力を組み合わせることで、迅速に生成され、かつ高い信頼性を持つ最終的なアウトプットを生み出す。
4.3. 事前防止策:AIを制約する戦略的プロンプティング
プロンプトに特定のフレーズを追加することで、誤解のリスクを劇的に低減させることができる。これには、提供された情報のみを使用するよう明示的に指示したり、不明な場合はその旨を回答させるよう求めたり、常に引用を要求したりすることが含まれる 5。
これらは、AIの行動を制約するための「ガードレール」となるフレーズである。
「アンチ・ハルシネーション」プロンプトの例:
- 「提供されたソースのみを使用して、…を説明してください。」 20
- 「主要な発見を要約してください。もし情報が文書内に存在しない場合は、『情報が見つかりません』と回答してください。」 5
- 「回答の各ポイントについて、直接的な引用と、ソースドキュメント及びページ番号を提示してください。」 5
これは一種の「防衛的プロンプティング」である。AIの潜在的な失敗モード(例:過度に協力的であろうとして情報の隙間を埋めようとする傾向)を予測し、それを防ぐための指示をプロンプトに事前に組み込む。これらのフレーズを習得することは、上級ユーザーにとって重要なスキルである。
4.4. データプライバシー、セキュリティ、およびコラボレーション
NotebookLMは、ユーザーのプライベートな利用を想定して設計されており、Googleはユーザーデータがモデルのトレーニングには使用されないと明記している 23。しかし、ユーザーは個人情報や機密情報を含むドキュメントをアップロードしないよう警告されている 11。
ノートブックは他者と共有し、共同作業を行うことが可能である 4。しかし、これには編集者(Editor)や閲覧者(Viewer)といったアクセス権の慎重な管理が不可欠である 25。クラウドベースのツールである以上、本質的なセキュリティへの配慮は常に必要であり、特に企業や機密性の高い研究で利用する際には、所属組織のデータガバナンスポリシーを遵守しなければならない。
コラボレーション機能は、「統合ワークベンチ」の概念をチームレベルに拡張する。研究チームは、共有のナレッジベースを共同で構築し、各メンバーがソースを提供し、資料群を尋問することができる。「ノート」セクションは、集合的な理解を形成するための共有スペースとなる。しかし、これを効果的に行うためには、「誰がソースのキュレーションに責任を持つのか?」「ピン留めされた発見を検証するためのプロセスは何か?」といった明確なプロトコルが必要となる。効果的なコラボレーションは、本レポートで概説したような共有されたメソドロジーの上に成り立つ。
表2:ハルシネーション緩和と検証のチェックリスト
以下の表は、分析的完全性の原則を、研究者がプロジェクトを通じて利用できる具体的で実行可能なチェックリストに変換したものである。これは、プロセスが堅牢であり、その結果が擁護可能であることを保証するための実践的なツールとなる。
| フェーズ | アクションアイテム | 根拠 | 関連ソース |
| 1. 準備 | 高品質なソースをキュレーションする: クリーンで構造化された、OCR処理済みの文書を使用する。無関係な「ノイズ」部分を除去する。 | AIの出力品質は入力品質に制約される。「Garbage in, garbage out(ゴミを入れればゴミが出る)」の原則。 | 3 |
| 2. プロンプティング | 具体的かつ明確に指示する: 単に「要点」ではなく「3つの主要な論点」を求める。複雑な質問は単純なステップに分解する。 | プロンプトの曖昧さは、グラウンディングされたシステムにおける解釈エラー(ハルシネーション)の主要な原因となる。 | 5 |
| 2. プロンプティング | 「ガードレール」フレーズを使用する: 「ソースのみに基づいて…」や「回答が存在しない場合は『不明』と回答せよ」といった指示を追加する。 | AIの行動を積極的に制約し、答えを捏造する代わりに無知を認めさせる。 | 5 |
| 3. 検証 | 引用をチェックする: すべての重要な情報について、引用リンクをクリックし、元のソーステキストを自身で読む。 | これが中核的な検証ループである。AIが提案し、人間が検証する。これにより最終的なアウトプットが信頼できるものになる。 | 4 |
| 3. 検証 | 一貫性チェックを行う: 同じ内容を少し違う表現で再度質問し、回答が安定しているか確認する。 | 回答に一貫性がない場合、AIが曖昧なテキストから弱い推論を行っている可能性を示唆する。 | 3 |
| 4. 心構え | 批判的思考を維持する: AIを神託ではなく、非常に高速だが誤りを犯す可能性のあるリサーチアシスタントとして扱う。最終的な判断は常に人間が行う。 | 批判的な監視なしにツールに過度に依存することはエラーにつながる。人間の専門家が最終的な権威である。 | 20 |
第5章:結論:リサーチワークフローの再定義
本レポートでは、GoogleのNotebookLMを用いて膨大な資料から網羅的に論点を抽出するための、体系的かつ再現可能なメソドロジーを提示した。その核心は、NotebookLMを単なる機能の集合体としてではなく、知識統合のための新しいワークフローを実践するための環境として捉えることにある。
このメソドロジーは、以下の4つの主要な柱に基づいている。
- ナレッジベースの構築: 分析の質は、ユーザーが提供するソースの質と構造によって決定される。効果的な利用は、AIの知識空間を意図的に設計する「キュレーション」から始まる。
- 体系的尋問フレームワーク: 偵察、広範なテーマ抽出、詳細な深掘り、そして関係性の比較分析という多段階のアプローチにより、場当たり的な質問を排し、網羅的かつ効率的な情報抽出を可能にする。
- 統合ワークベンチ: 「ノート」機能を活用し、抽出した情報を単に収集するのではなく、注釈を加え、統合し、さらにはそれ自体を新たな分析対象とすることで、より高次の洞察を生み出す。
- 分析的完全性の確保: 引用の徹底的な検証、防衛的なプロンプティング、そして批判的思考の維持を通じて、AIの速度と人間の判断力を組み合わせ、信頼性の高いアウトプットを保証する。
NotebookLMを習得することは、単一のスキルを学ぶことではない。それは、研究と分析に対する新しい思考様式と規律ある実践様式を身につけることである。このツールは、人間の研究者に取って代わるものではない。むしろ、厳格さと規律をもって用いられることで、膨大で非構造化されたデータから、深く、擁護可能な洞察へと至る道のりを劇的に加速させる、強力な認知的パートナーとして機能する。このメソドロジーを実践することで、ナレッジワーカーは、情報の洪水の中で溺れることなく、意味のある知識を構築し、より質の高い意思決定を行うことが可能となるだろう。
引用文献
- 【初心者向け】GoogleのAI「NotebookLM」とは?バックオフィス業務が劇的に変わる使い方を徹底解説 – RoboTANGO https://robotango.biz/knowledge/ai-notebooklm/
- NotebookLMの活用事例5選!業務効率化する便利な使い方とできることを解説 https://www.agaroot.jp/datascience/column/notebooklm-business-efficiency/
- Google NotebookLMのハルシネーションとは?AIの限界と対策を解説 | Hakky Handbook https://book.st-hakky.com/data-science/how-to-use-notebooklm-and-information-about-hallucination
- NotebookLMを使いこなそう:具体的事例で見る活用法|0xpanda alpha lab https://note.com/panda_lab/n/na0eb1d5bdf7e
- 【2025年最新版】NotebookLMの完全解説:使い方・料金・アプリ対応から活用事例まで https://takeshibaba.com/blog/ai-tools_18
- この世の中から議事録作成作業をなくしたい!NotebookLM で爆速化! – ソフトバンク https://www.softbank.jp/biz/blog/cloud-technology/articles/202412/notebooklm-minutes/
- 無料で使える最高のAIノート『NotebookLM』使い方と活用事例|AI-Bridge Lab https://note.com/doerstokyo_kb/n/n7edcc6bd70bf
- ノートブックの新しいソースを追加または検索する – パソコン – NotebookLM ヘルプ https://support.google.com/notebooklm/answer/16215270?hl=ja&co=GENIE.Platform%3DDesktop
- 自分専用AIを作る グーグル「NotebookLM」を家電取説・辞書・時刻表で使う – Impress Watch https://www.watch.impress.co.jp/docs/topic/1602337.html
- 10分でわかる Google の新サービス「 NotebookLM 」の使い方 https://workspace-hack.com/about-notebooklm/
- 無料で高精度な情報整理!GoogleのNotebookLMで資料を要約する超具体的な方法 https://nuco.co.jp/blog/article/lzHLBWZQ
- Notebook LMとは?使い方や料金、活用事例を徹底解説!【日本語 … https://www.ai-souken.com/article/what-is-notebooklm
- グーグル「NotebookLM」にみんな大好き「マインドマップ」機能が追加! – アスキー https://ascii.jp/elem/000/004/258/4258466/
- 「NotebookLM」の利用方法|生成AIの利用方法 – 東京経済大学 https://www.tku.ac.jp/iss/guide/classroom/ai/gemini-lm.html
- Day 4|NotebookLM使い方|NotebookLMの質問力を高めるコツと … https://note.com/mild_otter7070/n/n99bac8ea6355
- Day 9|NotebookLMで情報を比較・分析する方法|kumakuma https://note.com/mild_otter7070/n/n6c530162247a
- NotebookLM(ノートブック エルエム)とは?使い方まで徹底解説! | AI Walker – 株式会社Walkers https://walker-s.co.jp/ai/what-is-notebooklm/
- NotebookLMとは?使い方や料金・活用事例5選を詳しく解説 – AIsmiley https://aismiley.co.jp/ai_news/what-is-notebooklm-5/
- NotebookLMとは?GoogleのAIでメモが劇的に変わる! – サブスクらぶ https://subsc-love.com/what-is-notebooklm/
- NotebookLMのハルシネーション問題とは?原因と効果的な対策法|堺あきら(Aki) https://note.com/akira_sakai/n/n3e7fa61da59e
- GoogleのNotebookLMとは?基本機能と最新アップデートと始め方 – ドコドア https://docodoor.co.jp/staffblog/notebooklm/
- NotebookLMのハルシネーションは防げる?起こる原因と精度を高める5つのプロンプト術 https://asukaze.co.jp/notebooklm-hallucination/
- NotebookLMとは?RAG活用・機能・メリットから企業で活用する際の注意点を徹底解説! https://ai-market.jp/services/notebooklm/
- NotebookLMとは?日本語版はある?使い方料金プランを解説! https://www.sungrove.co.jp/notebooklm/
- NotebookLM情報漏洩リスクと対策|安全な活用事例と組織運用 – Hakky Handbook https://book.st-hakky.com/data-science/notebooklm-tips-for-secure-notebook-creation

